
Appian has spent years developing its own data fabric. This new layer within the company’s low-code automation platform allows data in different sources and systems to be addressed directly. We spoke with Appian CTO Mike Beckley about the impact of this new layer on data model creation, application development and performance.
We have come across many so-called fabrics over the past few years. NetApp had and has a data fabric and Fortinet has a security fabric, to name two. Recently, we also saw something similar pop up at SAP. Appian has had it for some time as well. Basically, all fabrics broadly do the same thing. They provide a link between environments and systems that was previously impossible. For example, because systems were not physically near each other, or because the content of the systems was inherently incompatible with each other.
In the case of data, these restrictions usually meant moving data around. Also, you often had to do something with that data to make it suitable for what you wanted to do with it. In other words, it was not easy to work with the available data in this way from a central location.
The above scenario is not particularly efficient. You’re constantly moving data around, which undoubtedly also results in a lot of duplicates. Keeping an overview is then not easy. In addition, such extra operations also irrevocably impact performance in general. Whether this is the performance of developers developing applications, or the performance of the applications themselves. Furthermore, uncontrolled distribution of data within organizations also causes security headaches. If you have no idea where the data resides, you cannot optimally secure it either.

Low-code data integration comes of age
With the data fabric, Appian aims to eliminate the above issues for users of the Appian automation platform. A few years ago during Appian World 2021, the first clear impetus for this was already given. Back then, Appian announced a functionality it called low-code data. With this, Appian brought low-code to data integration. In addition to making it possible to integrate data using low-code concepts, this functionality also means that data no longer needs to be migrated. So there is no need to transfer data to an Appian database.
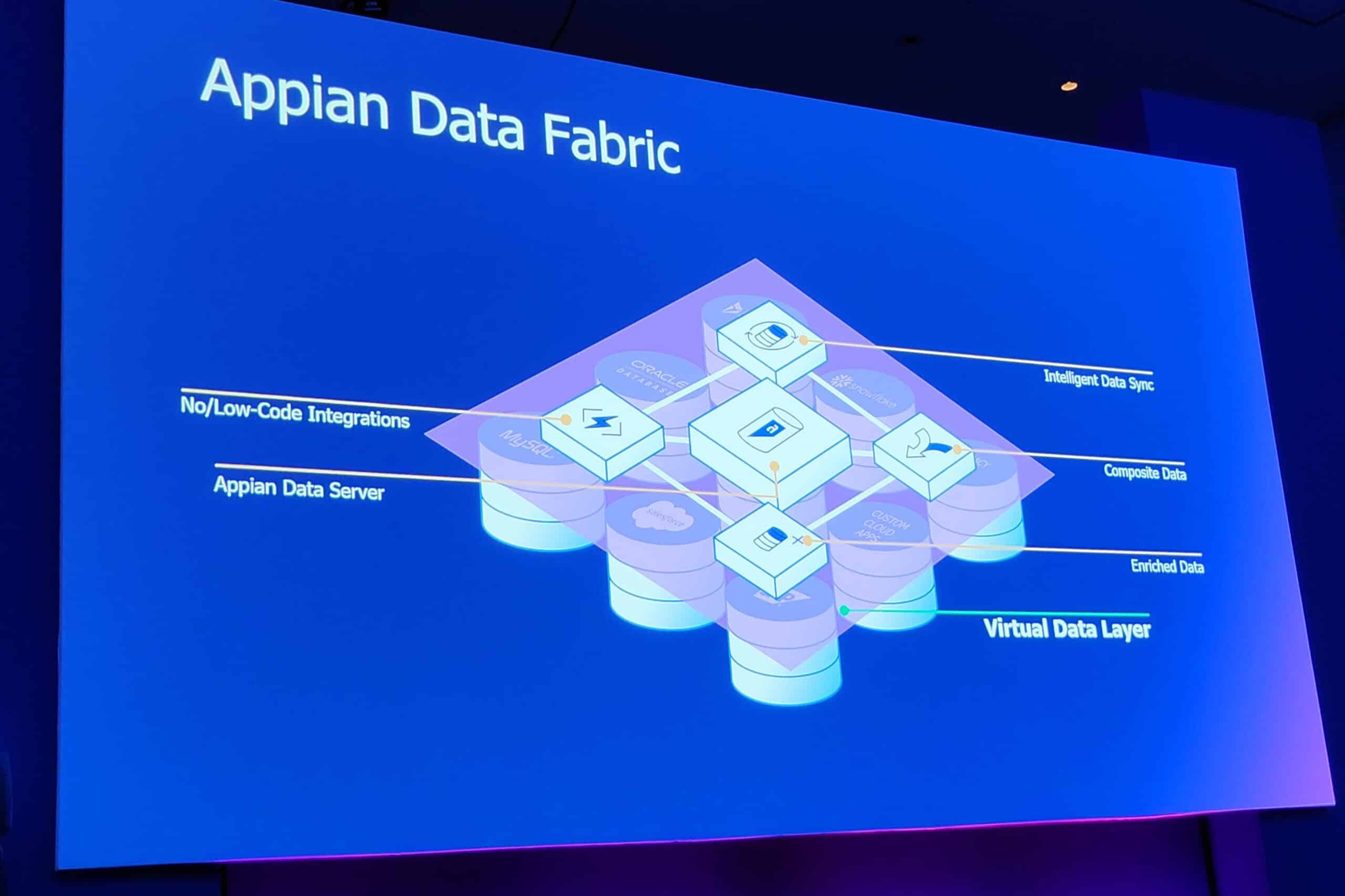
We are now just under two years down the road. In the meantime, Appian has continued to develop low-code data. It has now become the Appian Data Fabric. At its core is the Appian Data Service. This service ensures that all data from all different sources is centrally accessible. You can see at a glance what the connections are between data points and how they relate to each other. This makes it possible to centrally define a data model, Beckley points out. “You can work with this model, read and write data from it, as well as do queries and updates,” he indicates. So all this from a central point. You can think of Data Service as a kind of Business Intelligence, but not for using it to build dashboards for your sales department, but for developing applications.
Multiple layers of the Appian Data Fabric
On top of the Data Service is the semantic layer. That’s where the Data Fabric keeps track of all the data that matters, so to speak. Beckley himself refers to this section as the ontology, or the most essential part of the Data Fabric. This is where it sees what data “is,” what it should represent, and therefore knows what to do with it. This must be clear first. On this basis, it is possible to integrate the relevant data with each other. It is then also possible to set up integrations with different data sources at a higher conceptual level. This is in fact the final data model. You can use this for analytics, among other things.
On top of this layer within the Data Fabric comes another enrichment layer, where you can add additional value to the data. The result is that you can do cross database joins, something Beckley says has never worked well before. At least, not without moving a lot of data from multiple systems to a single database, but then it’s not formally a cross database join anymore, of course. With Data Fabric you can do it, without having to move data.
At the end of the day, the Appian Data Fabric makes it possible to understand the relationships between different data points. This is something you can’t do by default with data made available in a Data Lake. You usually have to put that data into a data warehouse before applications can use it. When developing applications, however, you want to integrate it into the application itself. That’s possible with the Appian Data Fabric. This also saves you a lot of time, according to Beckley, especially because it works very easily through low-code principles. In addition, you can also do a lot more with data, because you make the connections between different pieces of data much easier to understand.
Finally, in terms of the general features of the Appian Data Fabric, it’s worth reiterating that it speaks directly to the data in different systems. That is, there are fewer intermediate steps requiring APIs. Appian itself claims that the Data Fabric can reduce the number of complex API integrations by 20 to 60 percent. If true, that means a lot fewer APIs to maintain for the teams responsible for them. In addition, this is also safer, because now you don’t run the risk of building a sub-optimal API, with all its consequences. Beckley therefore sees the Data Fabric as “the beginning of a higher level of programming, a new semantic layer on top of what we already have.”
It is not a graph database
When we listen to Beckley’s story and based on what we see during his keynote at Appian Europe, we see parallels between the Data Fabric and a graph database. At first glance, the way the connections are made between different data points is identical. Beckley understandably does not want to say too much about how the underlying technology works. Nevertheless, he does want to make it clear that we are not dealing with a “common” graph database here: “We are using a multi-model database.” That means Appian can generate the same insights for data sources other than graph databases as well.
So the differences between Appian’s underlying database and graph databases are quite fundamental. Appian can integrate just fine with providers of that type of database, though. You can also easily use other platforms that fall under the heading of big data analytics as a source for Data Fabric. Beckley gives as an example the platforms of Quantexa and Palentir. That, in his words, is “great input” for Appian’s Data Fabric. By the way, we’ll be coming soon with an extensive article on Quantexa, so keep an eye out for that if you want to know more about that company.
Rapid adoption of Data Fabric
We heard from CEO Matt Calkins at Appian World last year that the adoption of low-code integration (and thus Appian Data Fabric) was going very fast. That adoption has not slowed down since then, Beckley says. In fact, 45 percent of Appian’s customers are already using Data Fabric. That in itself can be explained because Appian does not market the Data Fabric as a stand-alone component. It is an integral part of the platform. In fact, it is part of Appian Records. That’s more or less the basis of what Appian does.
However, another reason for its rapid adoption is also that you don’t have to fundamentally modify existing applications to make use of it. When asked how hard it is to adopt Data Fabric, Beckley answers that it’s a case of minor refactoring of applications. “Existing customers need to make some minor adjustments. The application needs to know who and what to call. This won’t take more than a few weeks,” he says. “For new customers, it is obviously not an issue at all, because they do not know that it was previously more difficult to make data from different sources centrally insightful and usable,” he adds.
Data Fabric is central to Appian’s vision
It should be clear that Appian is very serious about the Data Fabric. As far as we can tell, it is the central concept of the company’s message in the market. Last year and the year before it was all about low-code automation, but now it’s Data Fabric. When you consider that Appian has a strong vertical market approach, this shift in messaging makes sense. That is, Data Fabric allows the company to establish a compelling proposition.
In this regard, Beckley talks about customization as a feature, not a problem. Other platforms suffer from the latter; thanks to Data Fabric, Appian can actually position it as a distinguishing feature. “Data Fabric solves the trickiest part of customization,” he states. As an example, he gives extending a data model by a few fields. That was very complicated before, but very easy with Data Fabric. Within finance and insurance, two of the industries Appian has traditionally focused heavily on, this is going to benefit the company greatly, is his firm belief.
Data Fabric isn’t finished yet
To conclude this article, it is also good to take a moment to look to the future. The foundation for Appian Data Fabric within the company’s portfolio was laid several years ago with the announcement of low-code integration. That has since been further developed towards Data Fabric. However, Appian is not there yet. One of the ways in which Appian can improve the Data Fabric further, is by doing more in terms of data quality. That is one of the main pain points within organizations. Linking different data sources together is certainly very valuable, but if the quality of that data is not good, you do not get the insights and results you want and need.
Currently, there is already some functionality around data quality in Appian Data Fabric. Beckley, however, calls this “basic stuff”. This includes null handling, or dealing with empty cells, for example. It doesn’t go much further than this level op complexity at this point. This is coming, however, we gather from his words: “You can imagine a clear roadmap towards more functionality in this area.” We haven’t heard the last of the Appian Data Fabric, that’s for sure.