
With new features in Anthropic Console, developers should find it much easier to interact with Anthropic’s Claude-3 LLMs. The AI developer now offers functionality that tests and evaluates automatically generated prompts for effectiveness.
Creating the right prompts or queries is the best guarantee of getting the most value out of LLMs. Anthropic wants to greatly help end users in this regard by testing automatically generated prompts and evaluating them for their effectiveness.
For its Claude 3.5 Sonnet-LLM, the AI developer now offers new functionality for this purpose in its Anthropic Console interface. Over time, developers can realize better inputs based on the feedback and thus improve Claude-LLM’s responses for specialized tasks.
Usability
More specifically, the new environment helps users test and evaluate prompts created by the built-in prompt generator, introduced in May of this year. It allows them to test the effectiveness of these prompts in different scenarios. Users will find this under the Evaluate tab in the interface.
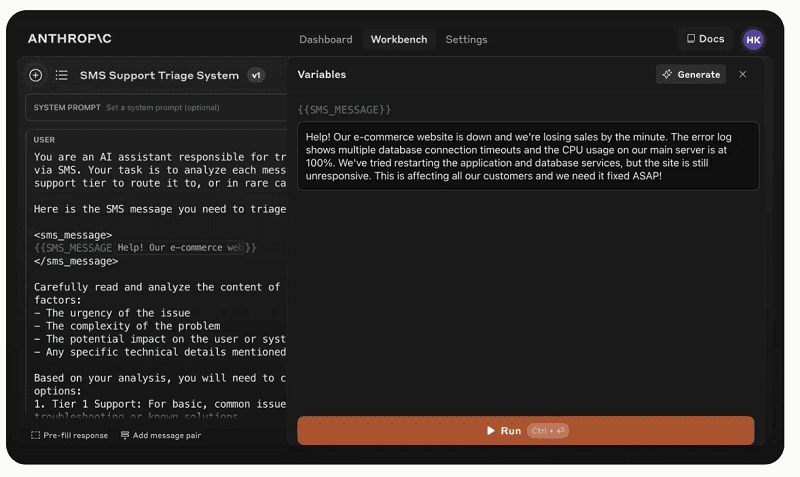
In addition, they can upload their own examples to the test environment or ask the Claude 3.5 Sonnet-LLM to produce a series of AI-generated test cases. In this way, developers can compare different prompts side by side in effectiveness and rate these examples on a scale of one to five.
The test environment is now available immediately to all Anthropic Console end users.
Also read: Anthropic launches initiative to develop better benchmarks for LLMs