
Nvidia releases new AI models and systems that should allow customers to perform AI workloads easier and faster. Added capabilities include the arrival of the giant NeMo Megatron AI training model, an upgrade for the Triton server solution and the introduction of Modulus.
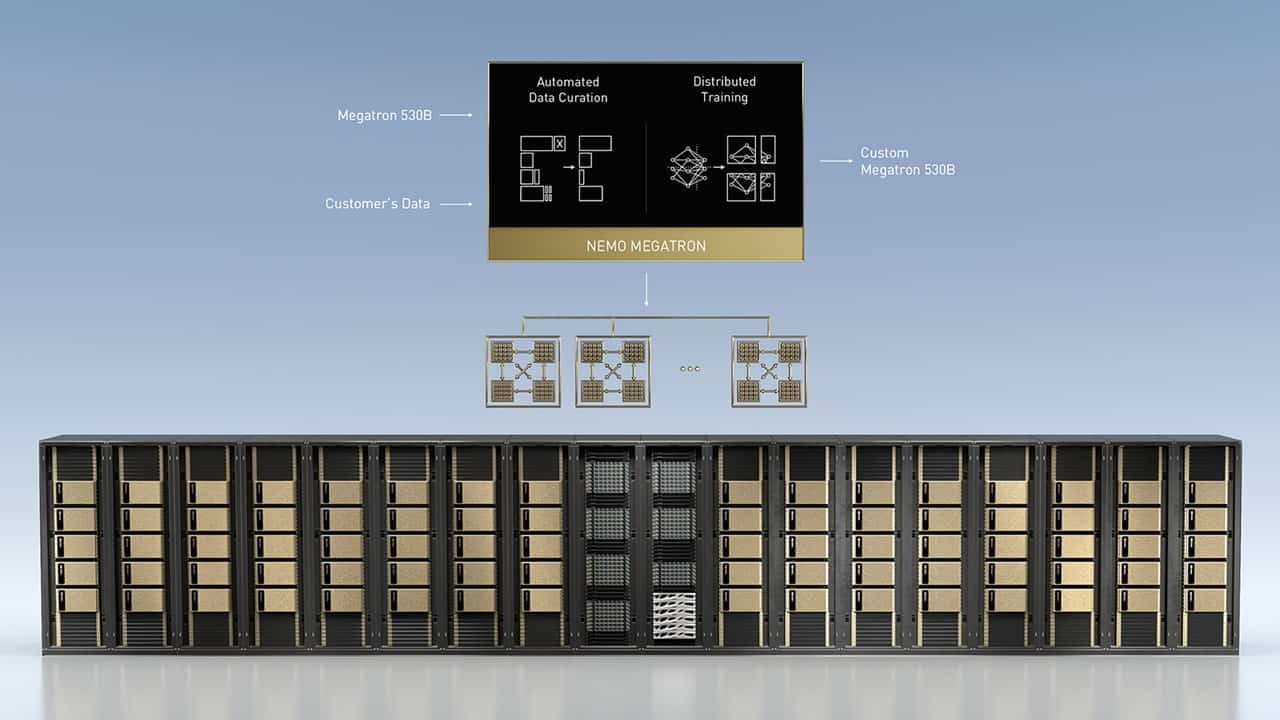
One of the most important announcements is the availability of the NeMO Megatron 538B AI framework. This framework is based on Megatron open-source framework that contains trillions of parameters for training natural language AI models.
With NeMO Megatron 538B, companies can customize the framework for training their own natural language-based AI models. The platform distributes all training activities across multiple GPUs. Said distribution reduces the complexity and time requirement of large language models (LLMs) training.
In addition, the framework can be widely deployed within a company’s private infrastructure or the (public) cloud, using the underlying DGX SuperPOD infrastructure. Nvidia claims its introduction is the largest HPC solution ever released.
Triton Inference Server
In addition to the arrival of the Megatron 530B AI framework, Nvidia has updated its Triton Inference Server. Functionality includes new multi-GPU and multi-node features to scale LLM inference workloads across different GPUs and nodes with real-time performance. The latter allows the Megatron 530B AI training framework to run on two DGX systems, thereby limiting processing speed on CPU-based servers and enabling the deployment of LLMs to real-time applications.
Introducing Nvidia Modulus
Moreover, Nvidia Modulus, an AI framework for developing machine learning (ML) models, sees the light of day. The Modulus framework should provide ML inputs required for building digital twin environments, which are commonly used for climate change prediction and industrial applications.