
The new general purpose large language model should help organizations realize generative AI apps that perform very well.
Databricks aims to achieve this by having DBRX rely on a mixture-of-experts (MoE) architecture based on the open-source project MegaBlocks. In particular, MoE addresses the limitations of GPT-like architectures (dense models) by splitting computational layers into multiple parts (experts), each performing its computations. New input to the model uses only the required experts; then the output is aggregated to arrive at the correct response of the model.
By using the MoE architecture, models can be trained with fewer compute resources. This promises the same model quality as dense models while making the training process faster than MoE. Databricks claims that DBRX achieves very high performance and is up to twice as efficient in terms of computing power as comparable LLMs. “DBRX uses a mixture-of-experts architecture, making the model extremely fast in terms of tokens per second, as well as being cost effective to serve,” responds co-founder and CEO Ali Ghodsi.
Performance compared to Llama, Mixtral-8x7B, GPT-3.5 and GPT-4
Databricks substantiates the high performance by providing benchmarks. First, it compares the DBRX to open-source LLMs Llama 2 70b from Meta and Mixtral-8x7B from Mistral AI. The new Databricks model performs better on language comprehension, programming, and mathematics. Grok-1 from xAI does come close to the performance of DBRX, but it is several percent off the Databricks model in terms of performance in most tests. The image below shows benchmarks of the comparable open-source models.
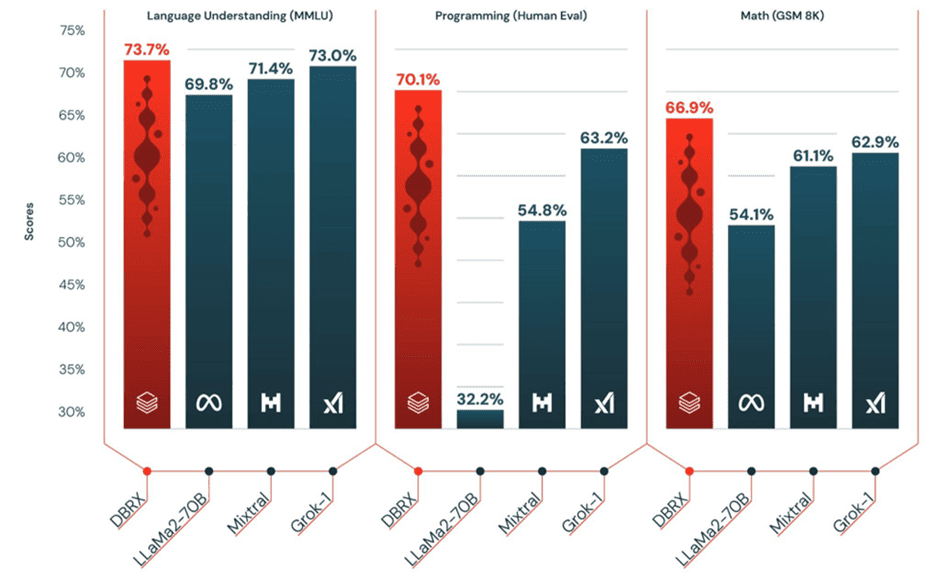
Ghodsi adds that DBRX “beats GPT-3.5 on most benchmarks, which should accelerate the trend we’re seeing across our customer base as organizations replace proprietary models with open source models.” However, GPT-3.5 is not open-source compared to DBRX. in the MMLU benchmark for language comprehension, GPT-3.5 scores 70 percent, in the Human Eval benchmark for programming 48.1 percent and in the GSM 8K benchmark for mathematics 57.1 percent. As you can see in the chart above, these GPT-3.5 scores are lower than those of DBRX.
Databricks also claims that it can even compete with GPT-4 on an internal use case like SQL. At the time of writing, we had no benchmarks to confirm this claim. Of course, we do have benchmarks of GPT-4 for language understanding, programming and math: scores of 86.4 percent, 76.5 percent and 96.8 percent, respectively. So in those areas, GPT-4 now scores significantly better than DBRX.
Combine with Databricks technology
The new DBRX model is available for free on GitHub and Hugging Face, for both commercial and research purposes. Databricks does say that combining DBRX with the platform’s Data Intelligence Platform leads to benefits. Namely, through the platform, companies can build customizable DBRX models with their own private data and the context capabilities of retrieval augmented generation (RAG) systems can be used.
The Mosaic AI component of the Data Intelligence Platform thereby helps to quickly build and deploy generative AI apps. Security and accuracy are central to this. The Data Intelligence Platform’s data management, governance, data sourcing and monitoring capabilities should complete the DBRX model.
For several months now, Databricks has been talking more about the Data Intelligence Platform, rather than the lakehouse. In a separate article , we discuss what this platform can do for businesses.