
Meta has announced Llama 3, the successor to the highly successful open-source model Llama 2. Along with the new LLM debuts Meta AI, one of the best AI assistants in the world, according to the company.
Llama 3 launches with two models: the compact Llama 3-8B (8 billion parameters), which can be run on relatively modest hardware, and Llama 3-70B. That’s one less variant than Llama 2, which had 7B, 13B and 70B offerings. The number of parameters greatly affects the accuracy of a model, as do the system requirements. Llama 3 is currently available on Amazon SageMaker. The models will soon also be released on Databricks, Google Cloud, Hugging Face, Kaggle, IBM watsonx, Azure, Nvidia NIM and Snowflake.
Meta says it will again embrace open-source to develop its own Llama models. The path to this setup has been and remains a unique one. Llama’s first model leaked in early 2023 after being intended only for researchers, after which Meta decided to launch Llama 2 directly as an open-source model. It is in stark contrast to parties like OpenAI, which has kept its most advanced GPT-4 model under lock and key.
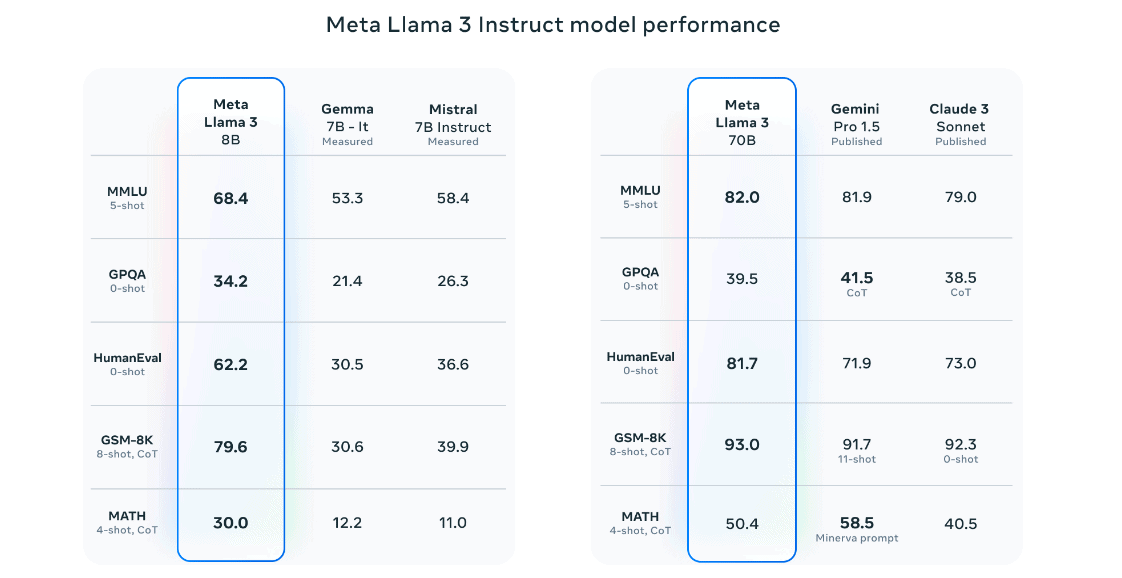
Impressive performance
Currently, AI benchmarks show a continuously shifting picture. Models from Google, OpenAI, Anthropic, Mistral and Meta each manage to excel in certain areas, although the exact testing methodology and models chosen tend to differ. Llama 3-8B, however, seems to come out well in known benchmarks, while the 70B variant, as expected, adds some extra performance. The higher the score, the more accurate or humanlike a model is, displayed through better reasoning and other skills.
To customize Llama 3 to their liking, developers can use several tools. Once the models are available on the aforementioned platforms, a large number of third-party training, fine-tuning, RAG and inferencing options exist. In other words, developers can attach their own data to Llama 3 to enable specific applications.
Meta itself offers updated components such as Llama Guard 2 and Cybersec Eval 2, in addition to the new Code Shield. The latter can filter out unsafe programming code from AI outputs.
Compared to Llama 2, version 3 is a lot faster, as well as more efficient. For example, Llama 3 uses a tokenizer with a vocabulary of 128,000 tokens and encodes languages much more efficiently than before: Llama 2 had “only” 32,000 tokens. This difference means that the new AI model can grasp more complex terms more easily. However, this may increase training time.
Meta AI: not yet in Europe
In addition to the Llama 3 model, Meta has immediately presented an application that runs on it: Meta AI. This chatbot can be used in its own window or in feeds, chat and searches within Meta apps. At least, for users in America, Australia, Canada, Ghana, Jamaica, Malawi, New Zealand, Nigeria, Pakistan, Singapore, South Africa, Uganda, Zambia and Zimbabwe.
Meta AI has yet to appear in Europe, then, which is a familiar phenomenon with such AI chatbots. For example, Google Bard (now renamed Gemini) did not appear in other countries within the EU until months after its initial release. The reason seems to be that European regulations are stricter on unsafe AI behaviour and tolerate less ambiguity about training data, although the rules have continuously changed in recent months.
Regardless, Meta AI looks like a full-fledged counterpart to ChatGPT and Google Gemini. Again, the approach is multimodal, allowing the chatbot to produce or analyze images in addition to text prompts. Meta AI is additionally integrated into Facebook, Instagram, WhatsApp and Messenger, similar to the approach taken by Microsoft for its own Copilot offering.
Dot on the horizon: Megalodon
There is more to report from Meta. For example, researchers at the company, along with colleagues at the University of Southern California, are proposing a new AI model: Megalodon. This LLM should solve seemingly intractable problems of current AI models. The Transformer, the fundamental architecture behind generative AI as we know it today, has a number of limitations. These relate mostly to the enormous amount of computing power required as a model scales and severe limitations on what an LLM can process at once.
With Megalodon, it would be possible to put extremely many tokens in the context window, allowing AI models to take in much more information than today. Mind you, this is a development that several parties are working on. Google even claims to enable infinite input for AI with “Infini-attention.”
In the case of Megalodon, Meta opts for Moving Average Equipped Gate Attention (MEGA), which was first unveiled in f2022. With this technology, the model moves attention gradually through an input in a way that uses computer memory far more economically than Transformers do. It’s an AI path Meta is taking that differs from, say, Microsoft, which until now has mostly tried to make models smaller.