
IBM has developed a generalization-based machine learning training that uses as little personal data as possible. This allows developers to build models that are highly compliant with European privacy laws and GDPR.
Training ML models with as little personal data as possible is difficult. Developers struggle to determine the minimum amount of personal data required to train ML models for accurate predictions and classifications.
IBM addresses the problem with a new training option that uses less personal data in the training datasets through a generalization process. The process keeps personal data usage to a minimum without overly affecting the models’ accuracy.
Generalization process
The training process removes or generalizes some of the input properties of the personal data being run. This involves ‘breaking’ the ‘value’ of a particular property into specialized values and general values.
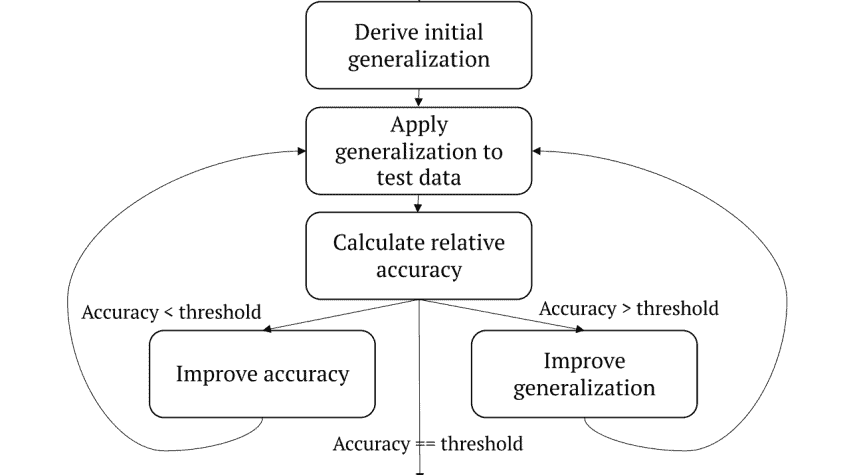
For example, a specific age is referred to as an age category with multiple age segments. Or, instead of ‘married/never married/divorced’, only the values ‘never married/divorced’ are assigned. Here, a value disappears, but because ‘divorced’ implies that someone was once married, the accuracy is maintained.
The generalized values are then analyzed as a metric. IBM chose the NCP metric for this purpose because of its data privacy standards.
Baseline comparison for accuracy
IBM researchers selected a dataset and trained multiple target models to create a baseline in their development process. They then applied generalization and calculated and recalculated accuracy. This was done with so-called decision trees that can be adjusted up and down. This allowed the degree of generalization to be increased or decreased. The final generalization outcome was then compared to that of the baseline, thereby allowing the accuracy to be determined.
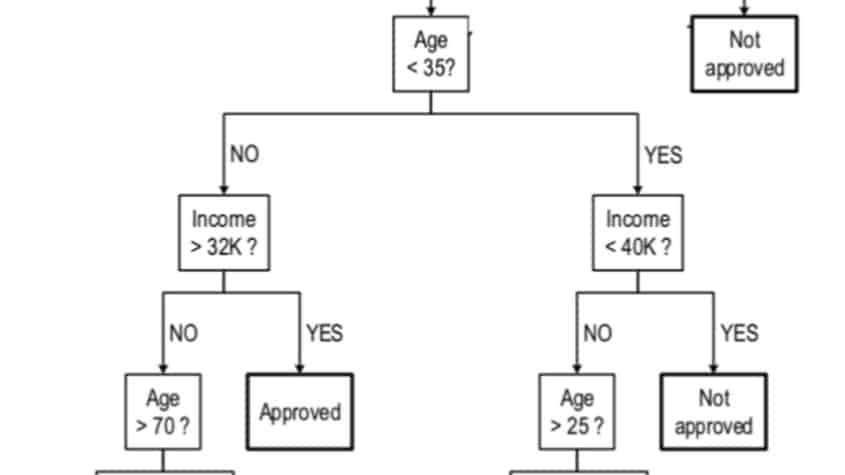
When the entire training process was generalized, the IBM specialists did not see accuracy fall below 33 percent. In some cases, they even achieved an accuracy of 100 percent through little generalization.
Cost savings
According to IBM, the new training method offers many opportunities for compliance with privacy laws and regulations. This training process also produces smaller data sets, allowing companies to save on data storage and management.