
Kubernetes is gaining a foothold in more and more places, including the edge. According to Symworld Cloud, as Robin.io has been called since last November, it is crucial that the underlying infrastructure can handle it. We visited this business unit of Japanese technology giant Rakuten to hear exactly what it means by this.
Symworld Cloud is all about what Partha Seetala calls Distributed Stateful Edge during a presentation we attended. Seetala is the founder of Robin.io. He and his employees built that company from the ground up with a clear goal. The idea from the beginning was to build a Kubernetes platform that focused on heavier use cases. By heavier use cases, we specifically mean workloads that place heavy demands on network and storage. The compute in these environments must also be as close to the workload as possible. At the edge, in other words.
Symworld Cloud is not for everyone
The most obvious application of Symworld Cloud’s platform is 5G, where a lot has to be done with data before some of it is sent on. From parent company Rakuten’s point of view, that’s a no-brainer. Yet Seetala emphasizes several times during his presentation that the edge is more than just 5G. As an example, he mentions fast food restaurants with drive-throughs. There, compute at the edge must also be present at all establishments. That, combined with Kubernetes, quickly becomes a deployment of thousands, if not tens of thousands of clusters.
In the above scenario, Symworld Cloud’s platform is in its element. Such a distributed edge environment also comes with its share of network and storage challenges. And that’s exactly what the Distributed Stateful Edge Platform is all about.
To get value out of the Symworld Cloud platform, you really do have to meet the conditions outlined above. So there must actually be (a lot of) data stored at the edge (i.e., it must be stateful). In principle, you can also work with Symworld Cloud in stateless environments, but then you won’t get everything out of it. In such cases, you can also go for other, more generic platforms on the market, Seetala points out. These include VMware Tanzu and Red Hat OpenShift.
Symworld Cloud’s three products
So Symworld Cloud is really not even so much about Kubernetes as it is about the platform underneath. Too often, Seetala still sees organizations just getting started with Kubernetes without looking at it properly. That’s not a good plan and won’t work.
Symworld Cloud specifically focuses on three components that ensure that cloud-native stateful workloads at the edge perform optimally. First is Symworld CNP (Cloud Native Platform), the fully integrated and full-stack Kubernetes platform optimized for specific workloads. The second product is Symworld CNS (Cloud Native Service). This is Symworld CNP’s cloud-native storage stack, which you can then use on top of another Kubernetes platform of your choice. This puts Symworld Cloud in direct competition with Portworx, now part of Pure Storage. The third and final product is the Symworld Orchestrator. This is all about managing the baremetal servers running Kubernetes clusters.
In the rest of this article, we’ll discuss these three products in a little more detail.
Symworld CNP
Symworld CNP, as already indicated, is a Kubernetes platform similar to VMware Tanzu and Red Hat OpenShift. During his presentation, however, Seetala wanted to clearly emphasize that Symworld CNP is a different beast altogether. Whereas Tanzu and OpenShift are broadly applicable, Symworld CNP really only focuses on the heavy use cases we talked about above. Below is a schematic representation of Symworld CNP.
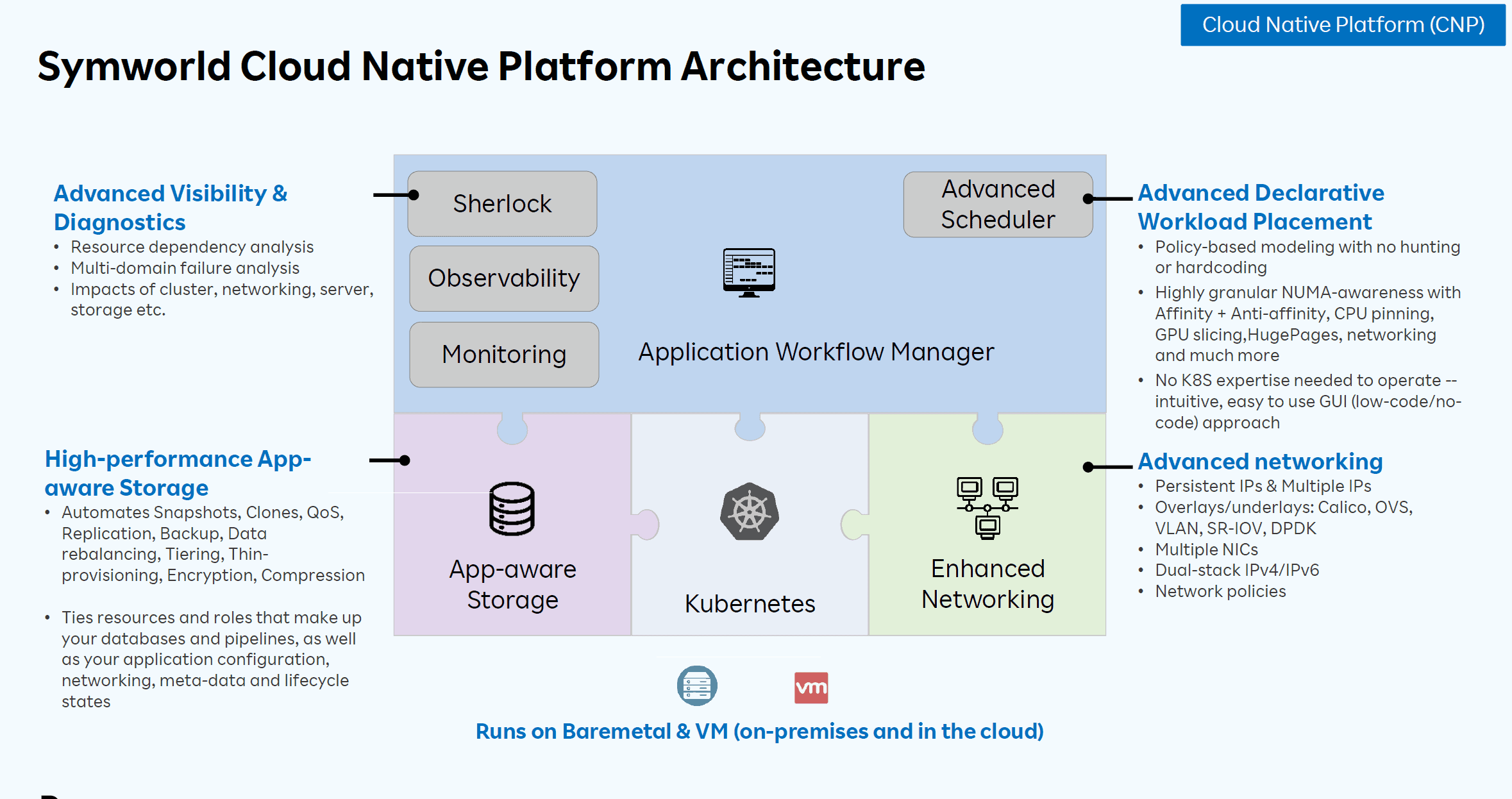
In terms of both storage and networking, Kubernetes poses challenges especially with large numbers of clusters. Basically, storage is a problem we have solved, Seetala points out, but still, with every new platform (such as Kubernetes), we have to re-examine storage to see if the architecture needs to be different. For Kubernetes, for example, DevOps manages storage. They especially want to be able to quickly add persistent storage to what they are developing. In addition, databases are also distributed. Those run across different servers. Finally, there is the issue of taking snapshots. That is also a different story within a distributed environment than in traditional environments.
In other words, storage must become app-aware. An application provides insight into things such as topology and constraints, but also sets requirements. If storage can handle this, you can deploy a full storage stack in a few clicks. Especially in stateful edge deployments, which involve tens of thousands of clusters, you can gain a lot with Symworld CNP. Hyperscalers seem to see that too, as Symworld Cloud is in talks with them to make it available there as well. Seetala doesn’t comment on the names of these hyperscalers. Nothing is official yet.
As for networking, Kubernetes by its nature does not take into account deploying the physical infrastructure layer to optimize it. That is, Kubernetes wants to apply as much abstraction as possible. This while applications, especially in demanding environments, need an accelerator (FPGA) with some regularity. Then you have to be able to make that connection. That’s what Symworld CNP can do.
Symworld CNP, by the way, is not just designed to run containers. The people at Symworld Cloud also understand that the world doesn’t switch to containers overnight. So it is possible to run them on baremetal alongside VMs at the same time.
Symworld CNS
Symworld CNS is only the storage stack of Symworld CNP, which you can run on any Kubernetes platform. So basically, you can now do everything you can do when it comes storage within Symworld CNP, but outside of that Kubernetes platform.
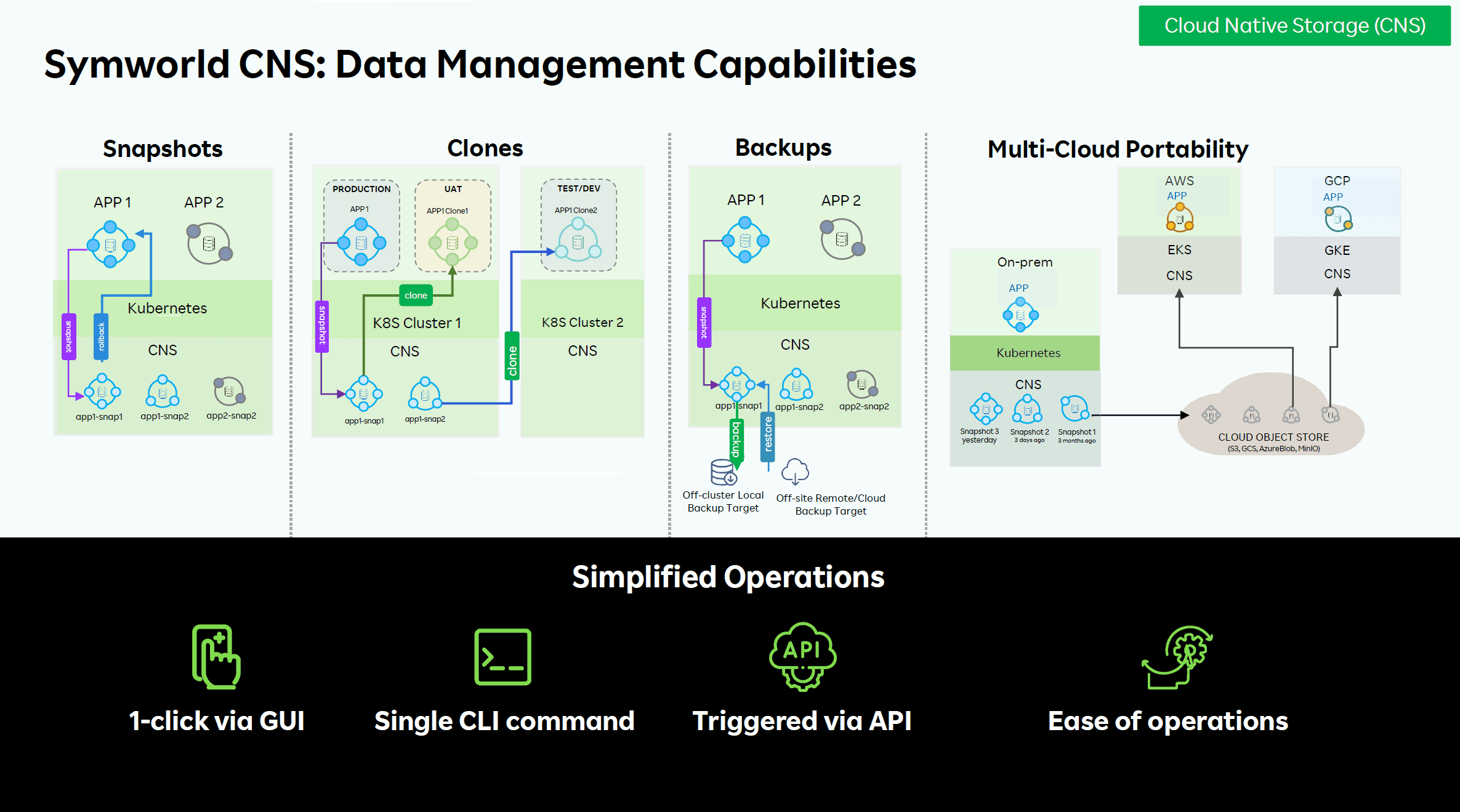
During the presentation, most of the discussion around Symworld CNS is around how Symworld Cloud’s approach differs from that of Portworx in particular. According to Seetala, Symworld CNS can deliver significantly better performance and is also more efficient because it does not rely on an existing file system. Portworx’s solution is based on Btrfs (Butter FS). That means Portworx can do little to nothing else with that layer, should it want to. Robin does not rely on any pre-existing technology like that. The people behind this company built it from the ground up, Seetala mentions. That allows for more control over the entire stack. At the end of the day, according to Seetala, this means a better user experience and better performance.
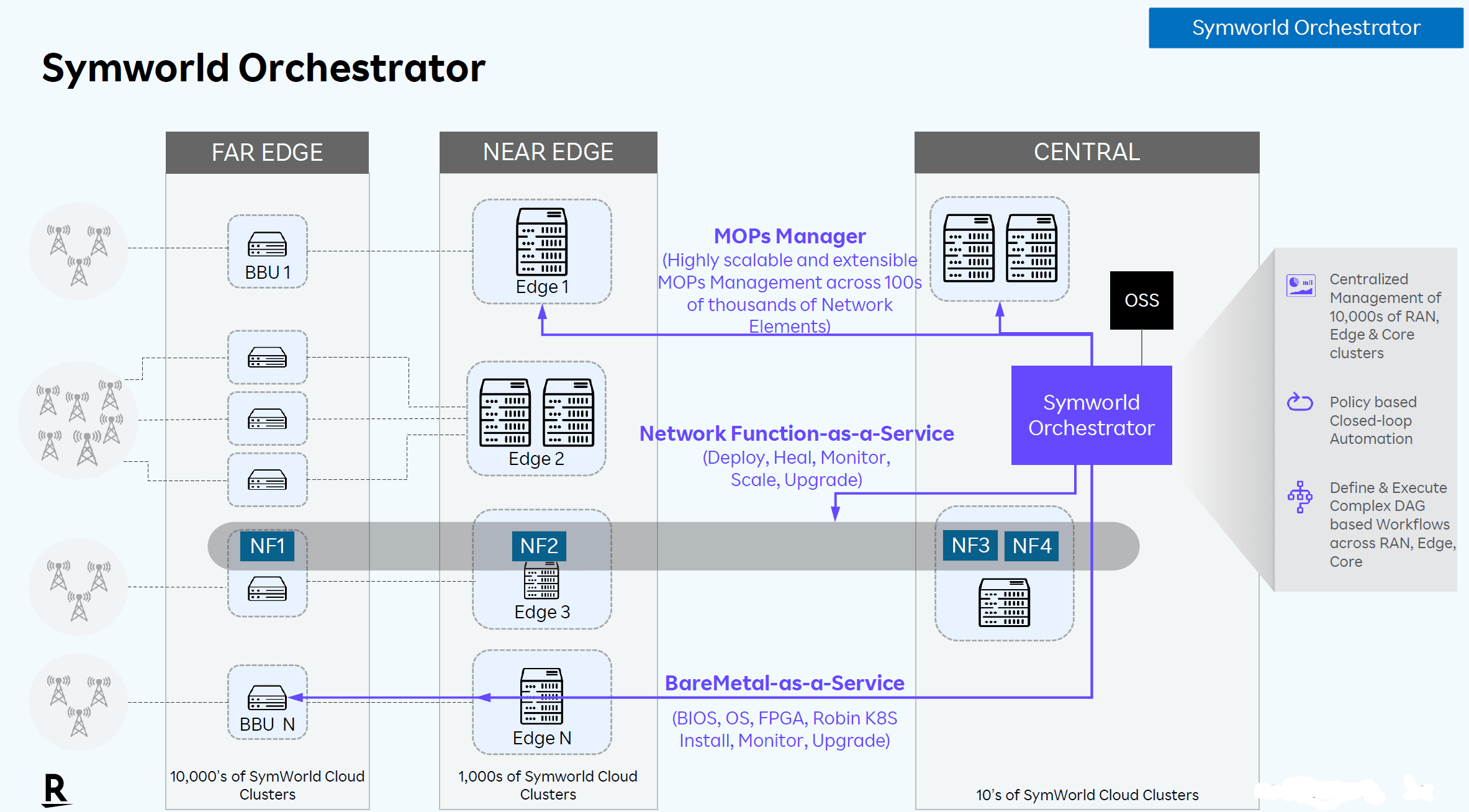
Symworld Orchestrator
The last component, Symworld Orchestrator, is certainly not the least important. In fact, Seetala explicitly names it a super critical product. This statement is not surprising, given the emphasis he has been placing all along on the importance of the underlying infrastructure. After all, Symworld Orchestrator is designed to manage the baremetal servers that run the many tens of thousands of clusters. If you don’t do that properly, he says, you can never scale to those kinds of numbers.
Conclusion
The three Symworld Cloud products give this business unit within Rakuten a fairly complete story toward the market. The decision to focus primarily on specific (edge) use cases may yet prove beneficial, if the edge really does end up exploding. If the claims are true that Symworld Cloud’s offering is so much better than the “old-fashioned” Red Hat OpenShift, based on 20-year old Ceph technology, and vSAN-based VMware Tanzu, it may cause the company to scale up very fast. Also, the developments with the hyperscalers could give Symworld Cloud a huge boost.
Furthermore, Symworld Cloud doesn’t rest on its laurels. For example, it is coming out with a self-built object store next summer and support for Arm is also on the roadmap. Arm so far is not really interesting for heavy use cases. One reason for this from a telco perspective is that FlexRAN still only runs on Intel chips. The decision when to launch Arm support depends also on what other players in the market develop. Marvell apparently is working on getting FlexRAN to run on Arm, but is not there yet. Once it runs on Arm, the heavy applications within the telco industry on Arm will come naturally as well.