Only having a modern storage infrastructure is not enough these days. Data needs to be available more and more easily, and it also needs to be available more and more quickly. Pure Storage is responding to this evolution with a number of announcements it is making today. We spoke about this with Marco Bal, Principal Systems Engineer at Pure.
Since its founding in 2009, Pure Storage has focused on developing and offering the most advanced and modern infrastructure possible. The emphasis on all-flash in the FlashArray systems has played an important role in this of course. But also consider, for example, the offering of UFFO, or Unified Fast File and Object storage, with FlashBlade. Making flash available for storage in lower tiers (with FlashArray//C) is also an example of this development.
Infrastructure alone is not enough these days, however. Increasingly organizations also have to ensure that they can make the data available. That means modernizing operations, among other things, making cloud functionality available on-prem. The idea is that users want to consume storage, and don’t want any fuss, Bal summarizes. Key words and concepts for this approach are visibility, scalability, instant availability, intelligent workloads and an SLA approach as we know it from the cloud.
Pure Fusion
To cover all the key words and concepts above, Pure introduces Pure Fusion today. This new (SaaS) service should enable “storage-as-code at an unlimited scale,” Bal indicates. It is an almost completely autonomous layer on top of your infrastructure, and should make it possible to scale infinitely. It also smartly handles the available storage in the physical FlashArrays (and FlashBlades) and the workloads that use them. In other words, the physical limits of a single array are basically not a problem when scaling. Everything is distributed across all available arrays.

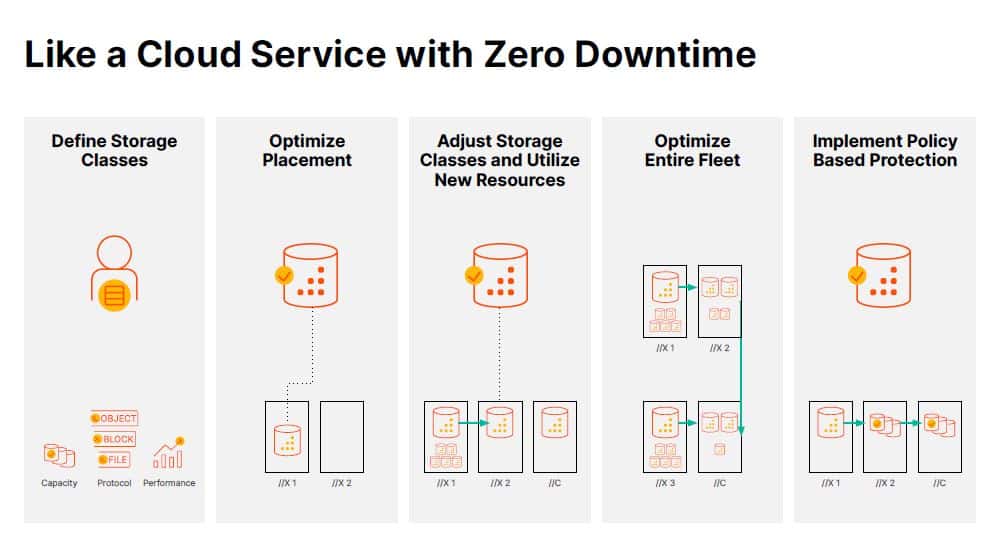
An important aspect of Pure Fusion is the link with Pure1, the AIOps platform from Pure Storage. Until now you could use this mainly for monitoring your environment. In combination with Pure Fusion you can use it to, among other things, define the storage class of specific data. Based on this storage class, Fusion determines where the data must be stored. Is fast storage needed, then the management platform chooses //X-arrays. If it is data for an application that is still under development, then it can also be stored on a //C array. You can also change this classification afterwards. This is often useful when you actually take an application into production and need faster storage.
Scaling up your so-called fleet of arrays is also all done behind the scenes within Pure Fusion. You can add arrays, move things around and balance them without impacting the front end. Pure uses the ActiveCluster synchronous replication technology for this, among other things. For the protection of the data, Fusion uses policies. Finally, it is also possible to forecast, in order to be ahead of all kinds of (support) tickets. If, for example, an array is half full within a short time, Fusion will respond appropriately.
Portworx Data Services
Earlier this year, we already touched on the first integrations of last Portworx, acquired by Pure last year, with the Pure platform. With this acquisition, Pure takes a clear step towards supporting (hybrid) cloud environments. In contrast to previous acquisitions such as Compuverde, Portworx seems to continue as a stand-alone part of Pure for the time being. It will therefore not be fully integrated into the existing offering. This also immediately indicates that Portworx is operating in an area that you could really describe as new territory for Pure. It is therefore clearly a step towards a broader portfolio, not a vertical addition to the existing range of solutions, as was the case with Compuverde.
The Portworx Enterprise platform is a storage and data management solution specifically aimed at Kubernetes projects. It is mainly about setting up the data services that you then link to applications. Today, in addition to Pure Fusion, Pure Storage also announces Portworx Data Services. The idea behind this new offering is that you can deploy data services on Kubernetes with a single click. This involves not only the storage layer, but also the management of the data source linked to it.
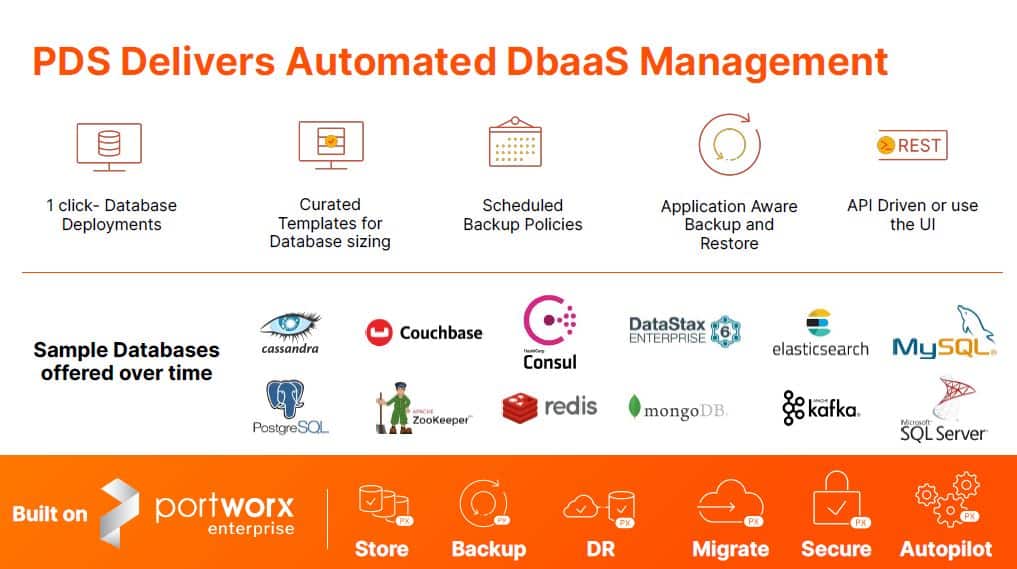
The goal of Portworx Data Services is to take away some complexity again when setting up new workloads. It offers almost completely automated DBaaS. You only choose the type of database or data service in a portal and input some specific characteristics there. Portworx Data Services will do the rest for you. In principle, it does not matter whether the data originates from Apache Kafka, Cloudera, SQL, NoSQL, Elastic, PostgreSQL, Spark or Microsft SQLServer, to name but a few sources. For closed-source data sources it is not yet clear what the licensing strategy will be for Pure. That is, will you be able buy licenses from Pure, or will it be a BYOL affair? That’s something Pure will have to make a decision about in the near future.
A final important component of Portworx Data Services is that Pure will be working with templates here. The idea is that, thanks to these templates, you don’t necessarily have to be a specialist to get started with the new service. Nor are you limited to Pure infrastructure. The new service works in both on-prem and in cloud environments. Portworx Data Services is available now as early access.
Updates in Pure1
In addition to the two big announcements above, there is also news around Pure1. The first update is that there will be proactive recommendations in the platform. That is, it will be possible to make suggestions to run workloads elsewhere if that yields better performance. This insight was already there before, but then the platform itself did not give the recommendations. As an admin, you had to keep an eye on that and interpret the data yourself.
A second update of Pure1 focuses on security. With SafeMode Snapshots you can better protect environments against ransomware in particular. Within Pure1, Pure Storage maps out which arrays have SafeMode enabled and which do not. You can also immediately see whether an array needs an update to enable SafeMode. The snapshots that Pure1 makes within SafeMode are immutable by the way. Malicious actors can no longer get to them. Pure does not protect against ransomware, but it does ensure that it is not possible to delete or encrypt all data.
A final update for Pure1 once again has to do with Portworx. There is now an integration between these two components. You can best think of this as the container version of the VM Analytics functionality, which has been part of Pure1 since 2018. The goal is to use this to provide insight into the entire chain of applications from the container to the arrays. This allows you to detect issues faster and also gain the necessary insights in terms of efficiently deploying your storage.
Pure Storage as a whole scales up (horizontally)
Pure always claims that the company was founded in 2009 with cloud management in mind. That is, Pure developed FlashArray from the beginning with things like modularity and scalability in mind. The company itself now talks about “cloudifying” infrastructure. With today’s announcements, it has again taken some clear steps in that direction. This is necessary too, because customers now have more demands and wishes. An extremely fast and highly available infrastructure alone is no longer enough. In the field of operations (with Pure Fusion) and services (with Portworx Data Services), Pure is now taking pretty big steps towards answering those wishes and demands.