
Not a state hacker or a DDOS attack by a botnet, but a simple erroneous update file that spread like a virus at high speed through the global Cloudflare network. Why did this shut down the company’s services? And how unique was this problem?
The outage on November 18 was the largest Cloudflare has suffered since 2019. Services of all shapes and sizes, from ChatGPT to X, Spotify, Canva, Authy, and the IKEA website, went offline as a result. Technically, there was nothing wrong with these customer-facing services themselves or indeed the end users’ connection, as the 500 error message regularly showed. Unusually, it was the second link in the chain between user, router and host that broke. The online path to the affected global services ran through at least one Cloudflare system. The culprit was located in the CDN provider’s Bot Management system, a separately purchased offering that blocks malicious bots without CAPTCHAs. When everything is working properly, it removes friction from the user experience. Cloudflare uses various signals to determine whether or not someone is a regular user, allowing them to access the website — without said user ever noticing that this service is active.
No foul play
Cloudflare’s staff initially thought they were being targeted by a “hyper-scale DDoS” attack, says CEO Matthew Prince. That’s not such a crazy initial thought to have: record after record is being set by massive botnets that are being blocked by Cloudflare and Microsoft, among others. In January, the record was “only” 5.6 Tbps, or 700 gigabytes per second, fired by approximately 13,000 IoT devices. By September, this had already risen to 22.2 Tbps. Both these attacks were constrained by Cloudflare, which reported on them afterwards.
However, the outage was actually caused by Cloudflare’s own system. Its cause involved a so-called “feature file,” a file that tells Cloudflare software what kind of malicious behavior bots may exhibit. Such behavior is constantly changing in a never-ending cat-and-mouse game between threat actors and suppliers such as Cloudflare. The Bot Management system receives this feature file, which can contain up to 200 features. That’s well below the actual number of features that the system uses at runtime, according to Prince. It usually only uses around 60 when the system is running.
To stay ahead of cyber adversaries, the feature file spreads rapidly across the global network. This time, however, it was twice as large as intended, exceeding the file limit within the Cloudflare software for the feature file. As a result, it contained more than 200 features, causing the system to “panic,” in Prince’s words. This abundance of features was caused by an erroneous change in the permissions of a database system. Multiple entries appeared in the database for the now infamous feature file, with all the consequences that entailed.
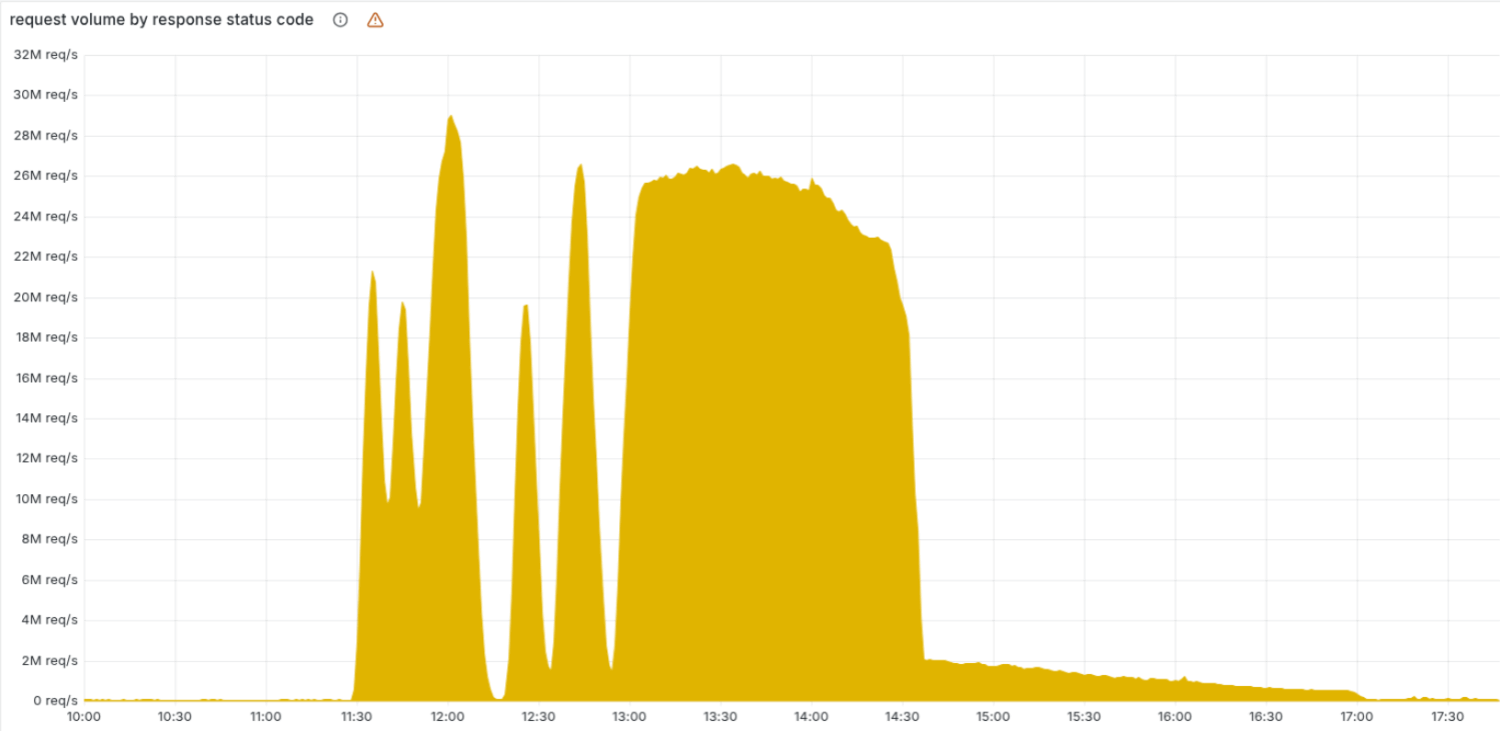
The consequences were immediately noticeable at 11:20 a.m. Central European time, but the malfunction was extremely unusual in its behavior. Normally, with a generic DNS provider problem, one would expect to see a spike, usually local in nature, due to, for example, a power outage in a data center. However, users worldwide were sometimes able to access the requested internet services and sometimes not. Intermittent problems are, quite frankly, weird in an IT setting. Even more so as access fluctuated at five-minute intervals as that is the frequency of Cloudflare’s ClickHouse database cluster running a query to generate the new feature file.
In short, it was an unusual situation that smacked of a deliberate attack. The latter turned out not to be the case. It took Cloudflare more than three hours to figure out exactly what was going on and for its quick fix to be implemented. However, as soon as each ClickHouse node had generated an incorrect configuration file, all access to websites that depended on the bot-blocking module was denied. That happened around 1:00 p.m. CET. An hour and a half later, Cloudflare’s remediation took effect, and shortly after 5:00 p.m., the number of error messages had returned to its normal, low level.
Complex operation
Websites don’t always reveal which reverse proxy they use, but four out of five that do, use Cloudflare for this purpose. The company itself states that 20 percent of the global web flows through its network. Since the internet is by definition intimately connected, the remaining 80 percent also often makes indirect use of Cloudflare. In other words, click on just about any link and chances are that Cloudflare will be found in the mix of network traffic somewhere down the line.
This pervasiveness comes with a great deal of responsibility. The company, which is just about 20 years old, has owed its success to a combination of user-friendliness and a willingness to tackle the cyber threats that have emerged since its founding. Thanks to Cloudflare, all kinds of network traffic issues can be solved with a single mouse click. Aided by a freemium pricing model, customers can quickly and affordably cover many of the prerequisites for running a website. However, this alone would not have been enough for securing and serving today’s internet. As mentioned earlier, DDoS attacks are reaching new records, but more importantly, widespread bot traffic can continuously take down websites wherever, whenever. Cloudflare usually manages to prevent this on a much smaller scale per target, but all the time and at a global scale. That does not exonerate the company from culpability with yesterday’s outage, but it should be noted that its task is a great endeavor indeed.
Echoes of CrowdStrike
Anyone reading the description of the Cloudflare problem above may already have made the connection with another global outage, namely that of CrowdStrike on July 19, 2024. There, a faulty update led to blue screens of death, canceled flights, inaccessible websites, and hospitals having to shut down their operations for the day. There are many parallels with the Cloudflare problem: even the error in the problematic files is roughly the same at least in terms of its characteristics. At CrowdStrike, 21 input fields were sent via an update to the Falcon security sensor instead of the expected 20, leading to the now-infamous global endpoint security meltdown for millions of devices. In the case of Cloudflare, a similar update file grew to twice its normal size and wreaked havoc in a similar fashion. In short: the software, however different, was unable to compensate for data that did not fit the usual format.
The question is whether such software errors can ever be completely prevented. Cloudflare emphasizes that it places limits on file sizes to improve performance and allocate memory. Files that need to be distributed on a global scale in a very short time must be compact. Logic designed to correct erroneous database information may lead to a slower rollout. It would cost an untold amount of money to distribute more data than is absolutely necessary on a five-minute basis with the kind of scale Cloudflare’s network has.
The general parallel between the incidents at Cloudflare and CrowdStrike is that these are fast-moving companies that aim to provide customers with the protection for tomorrow’s threats today. In both cases, this almost always works well. However, when things go wrong, a large part of the internet or a large number of critical devices can fail. Expecting customers to have an alternative at the ready is impractical, as doubling up on your reverse proxy for such a rare event would appear an irresponsible expense, not to mention implementing it for real when all hell breaks loose.
Conclusion: a hard lesson, but a freak incident
CEO Matthew Prince is clear about what happened. “An outage like today’s is unacceptable.” The company will therefore not assume that this freak incident (in our estimation) can never happen again. Prince’s clear suggestion is that, as with previous outages, Cloudflare will look for ways to build more resilient systems. Obviously, this cannot be at the expense of the DDoS-resistant features provided by the Bot Management system.
There is a chance that Cloudflare will strengthen its control over rapid updates, for example by verifying file sizes from now on before pushing them to its many Clickhouse nodes. However, a problem like this always seems to have a basic, yet unique cause. Like other vendors, Cloudflare does not know what it does not know, as simple as that may sound.
Globally active security companies, including Cloudflare with its anti-bot measures, bear a responsibility that customers need to be aware of. It is not easy to always be cognizant of the control you give away for convenience. Downtime is the big bogeyman for businesses and can even cause them to go bankrupt. In principle, no company should be completely dependent on another for its survival. In the case of Cloudflare outages, it would have to be a very long-lasting incident for customers to truly worry about its continued existence. Most outages are short-lived. But be aware that they can be serious enough to cause you to lose a working day or more of availability. It is best to figure out in advance exactly what you would do in that case. Some will undoubtedly have come up with a plan on the spot yesterday. They may be a good template to work from later on with less head-scratching and nail-biting than was the case this time.
Read also: Cloudflare brings 50,000 LLMs within reach with Replicate acquisition