
Meta recently presented its new early-fusion multimodal LLM Chameleon in a research paper. Using this model, the company hopes to enable new AI applications that can process and generate both visual and textual information.
Meta is not sitting idly by in the AI race and has presented Chameleon, a prototype of a ‘native’ multimodal LLM. Native means it is multimodal right from the start, rather than the ‘late fusion’ multimodality as in models like DALL-E. In the latter case, different components are trained in different modalities and fused together later. Chameleon is thus a multimodal LLM right from the start, or ‘early fusion’.
This means the LLM can directly handle tasks previously performed by different models and can integrate different types of information better and more directly. This allows the model, for example, to more easily generate sequences of images or text or combinations of these. At least, that is what the research paper claims, as Meta has not yet released Chameleon.
Early-fusion model
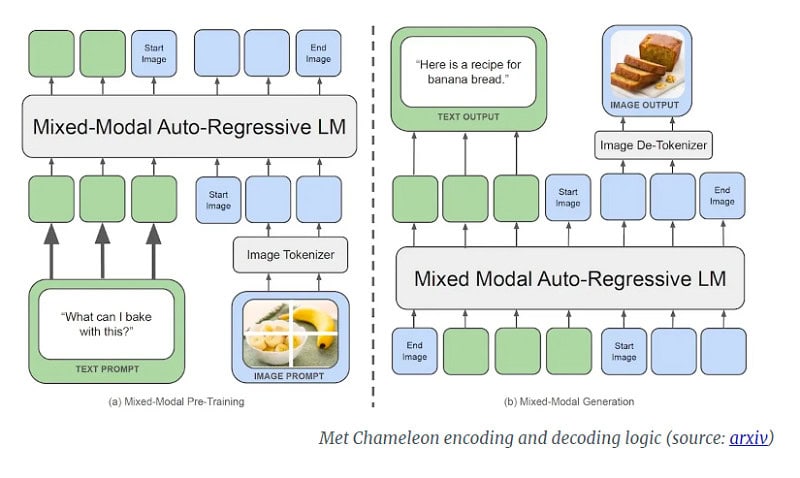
More specifically, Chameleon by Meta uses an ‘early-fusion token-based mixed-modal’ architecture. This means the model from the start learns from an interwoven combination of images, code, text and other inputs. Images are converted into discrete tokens, much like language models do with words. In addition, the LLM uses a mixed ‘vocabulary’ consisting of images, text and code tokens. This makes it possible to create sequences that contain both image and text tokens.
According to the researchers, Chameleon can best be compared to Google’s Gemini, which also uses an early-fusion approach under the hood. The difference, however, is that Gemini uses two separate image decoders in the generation phase, while Chameleon is an end-to-end model that both processes and generates tokens.
Training and performance
Early-fusion LLMs are difficult to train and scale, but Meta’s specialists say they have found an answer. They have modified the LLM’s architecture and added training techniques.
The model training happens in two stages using a dataset of 4.4 trillion tokens of text, image-text combinations, and sequences of interwoven texts and images. Two Chameleon versions were trained using these: one with 7 billion parameters and one with 34 billion parameters. The training session lasted more than 5 million hours on Nvidia A100 80GB GPUs.
Ultimately, these training sessions resulted in Meta’s Chameleon being able to perform various text-only and multimodal actions. In the area of visual generation, the LLM of 34 billion parameters outperforms LLMs such as Flamingo, IDEFICS, and Llava-1.5 based on benchmarks.
The model performs on par with Google’s Gemini Pro and Mistral AI’s Mixtral 8x7B in terms of text-only generation.
AI race continues
Meta introduces their latest LLM in an ever-changing AI landscape. Last week, OpenAI introduced its latest GPT version, GPT-4o. Microsoft introduced its MAI-1 model a few weeks ago, and Google launched Project Astra, which could also compete with GPT-4o.
It is not yet known when Meta will release Chameleon.
Also read: ChatGPT now talks in real-time, new model GPT-4o available for free