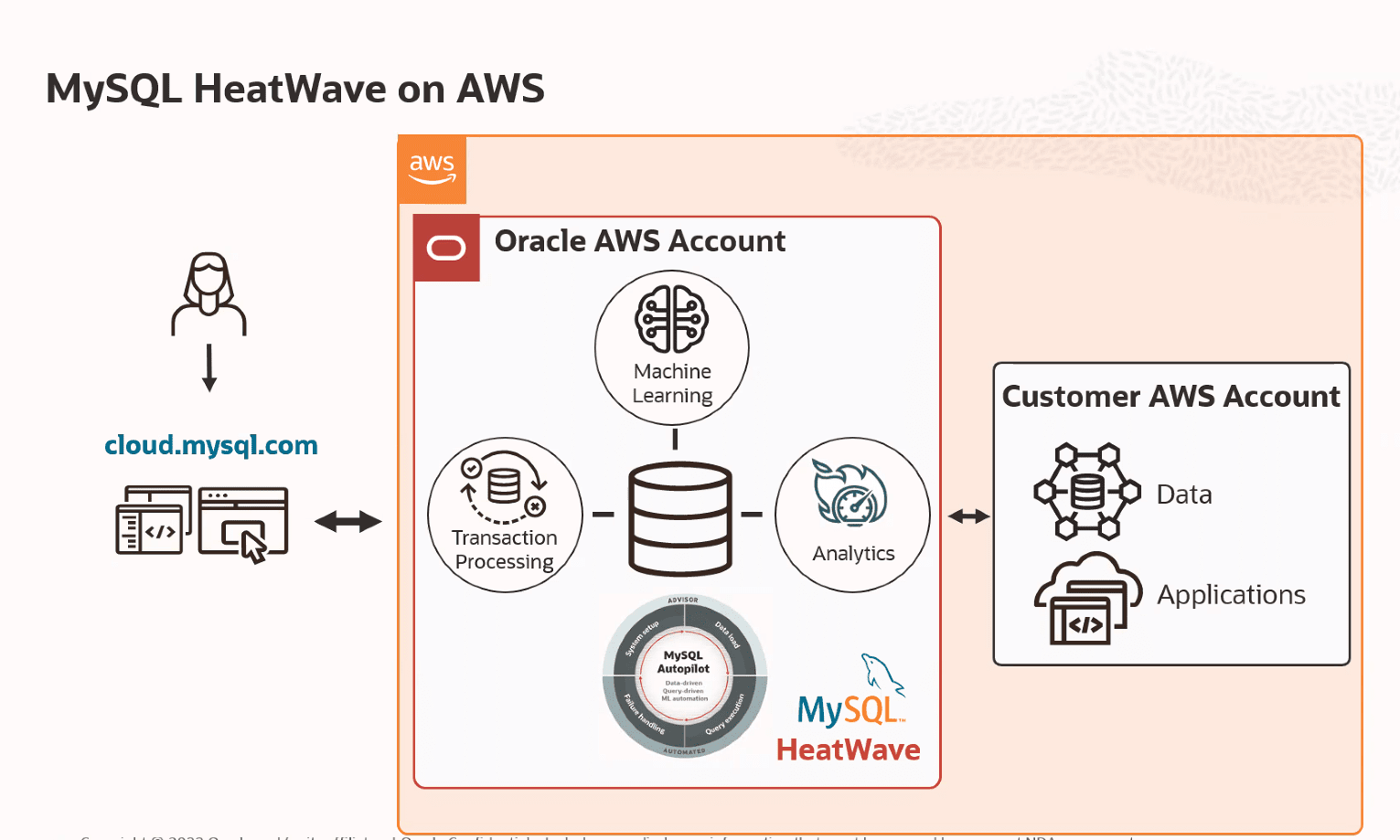
MySQL HeatWave on AWS is intended to provide a native experience for AWS customers and promises much better performance than AWS’ own offerings, at a significantly lower cost.
In addition to regular updates to its own OCI environment, Oracle has also clearly set itself the goal of offering Oracle services on other public clouds. We recently saw an example of this with the expansion of Interconnect for Azure with the Database Service for Azure. This makes it possible to run Oracle databases without leaving the Azure environment. You can see today’s announcement as a similar step. Only now it’s not about Microsoft Azure, but about AWS. That’s a bit more controversial, of course, because Oracle and AWS are not the best of friends. That is, Oracle’s Larry Ellison usually has some remarks about AWS at Oracle events, to which AWS then responds (usually without specifically naming Oracle as the recipients of the comment).
In an ideal world for Oracle, it wouldn’t have to make announcements like the one today and, earlier, the one around Interconnect for Azure. In the case of HeatWave, Oracle would no doubt much prefer that customers purchase this query accelerator within OCI. But that is simply not the reality. The cost that AWS charges to move data from their environment elsewhere is quite high. In addition, there are simply many customers who use other services from the AWS ecosystem (S3 for example). So they don’t want to migrate at all. That’s why Oracle has taken the step of making MySQL HeatWave available on AWS.
A quick refresher: what is MySQL HeatWave again?
Earlier this year, we wrote an article about the addition of Machine Learning to MySQL HeatWave. In it, we also explained what HeatWave actually is. You can of course read that article again by clicking here. We reproduce part of our explanation from that article below for convenience.
HeatWave is a so-called query accelerator. As that term suggests, the goal of HeatWave is to make MySQL queries run faster. It is also part of the MySQL database, which was originally designed for transactional purposes, not necessarily for the highest performance in terms of the queries themselves. Hence, for things like best performance and scalability, users often use multiple databases side by side. And thus have to migrate a lot of data between databases. If MySQL HeatWave does what it promises, you don’t have to do that anymore.
Adding a query accelerator to a transactional MySQL database may not sound that complicated. However, Oracle has been working on MySQL HeatWave for more than a decade. As such, today’s announcement is quite a big deal.
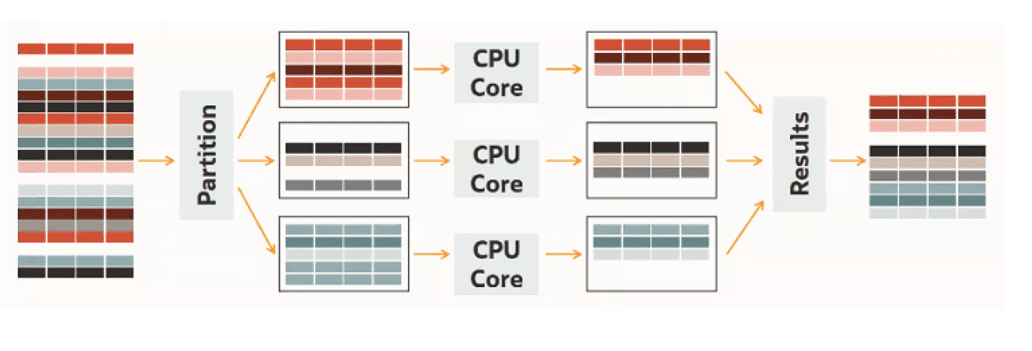
MySQL HeatWave is massively parallel and massively partitioned. Those are the two prerequisites for providing both excellent performance and scalability. Data is first divided into partitions, which are then processed in parallel. At the end, HeatWave merges the partitions back together. Below you can see how that works schematically.
Big promises from Oracle about MySQL HeatWave on AWS
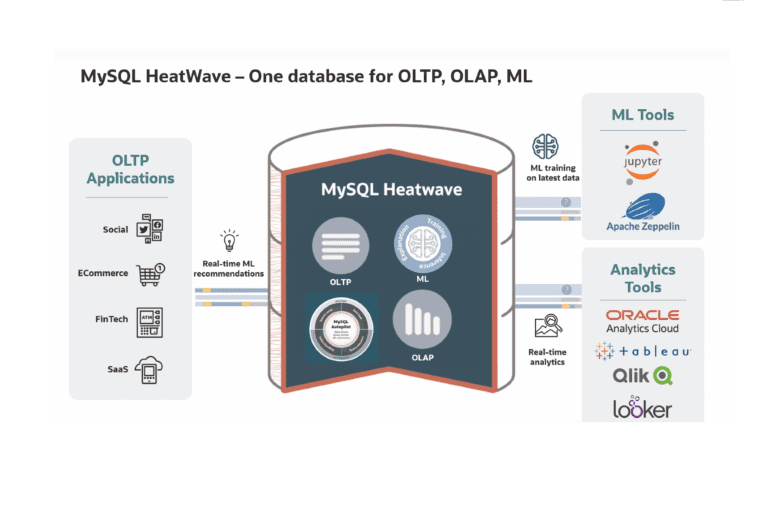
By making MySQL HeatWave on AWS available, Oracle has created an option to do transactional workloads, analytics and machine learning within AWS in a single database. To do this, a customer doesn’t have to provision and pay for an instance on AWS themselves. Oracle takes care of all that, we hear from a spokesperson during a briefing earlier today. That is, you can provision the AWS instance via cloud.mysql.com. Oracle takes care of the rest. Below you can see schematically how this works.
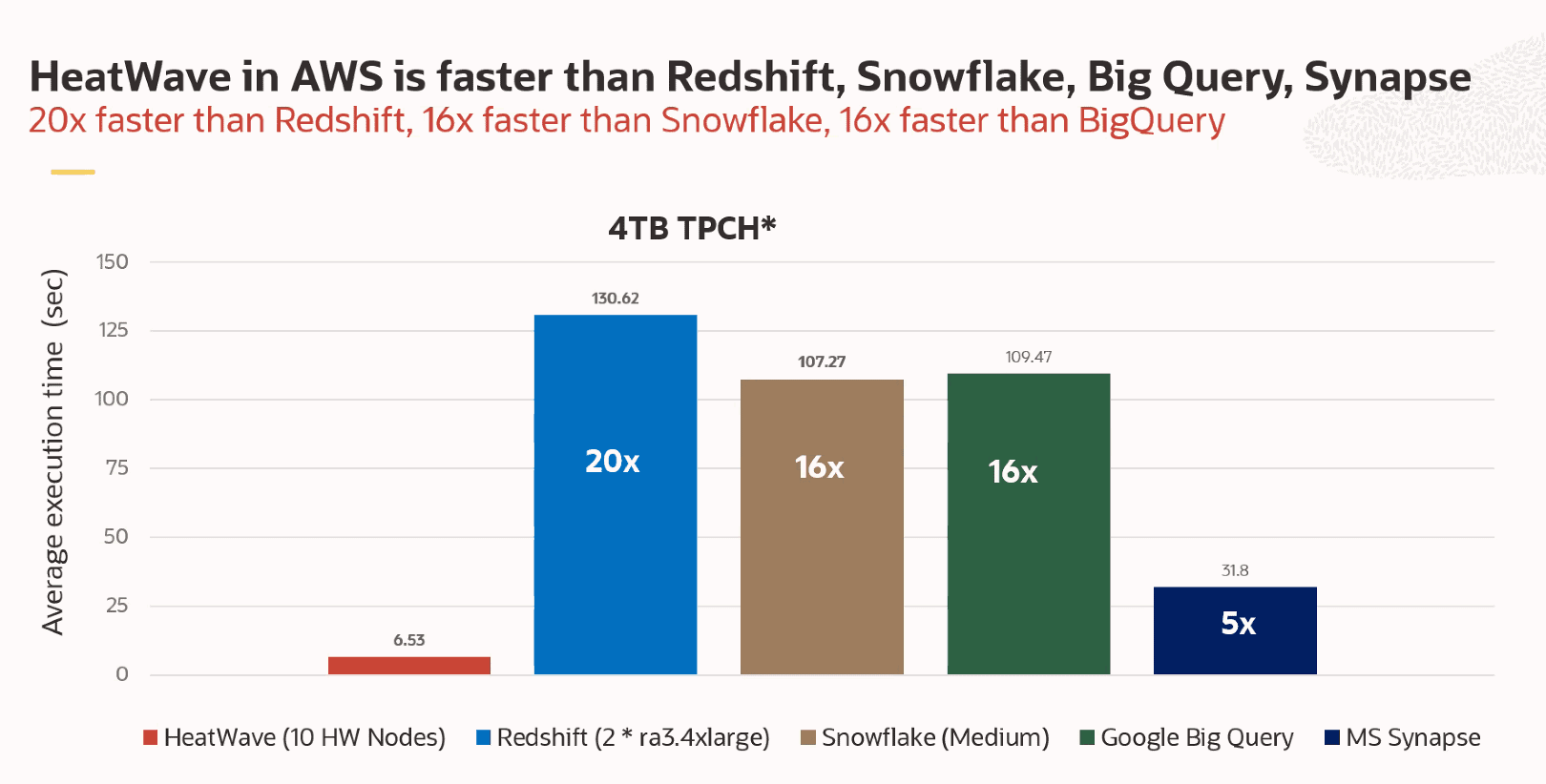
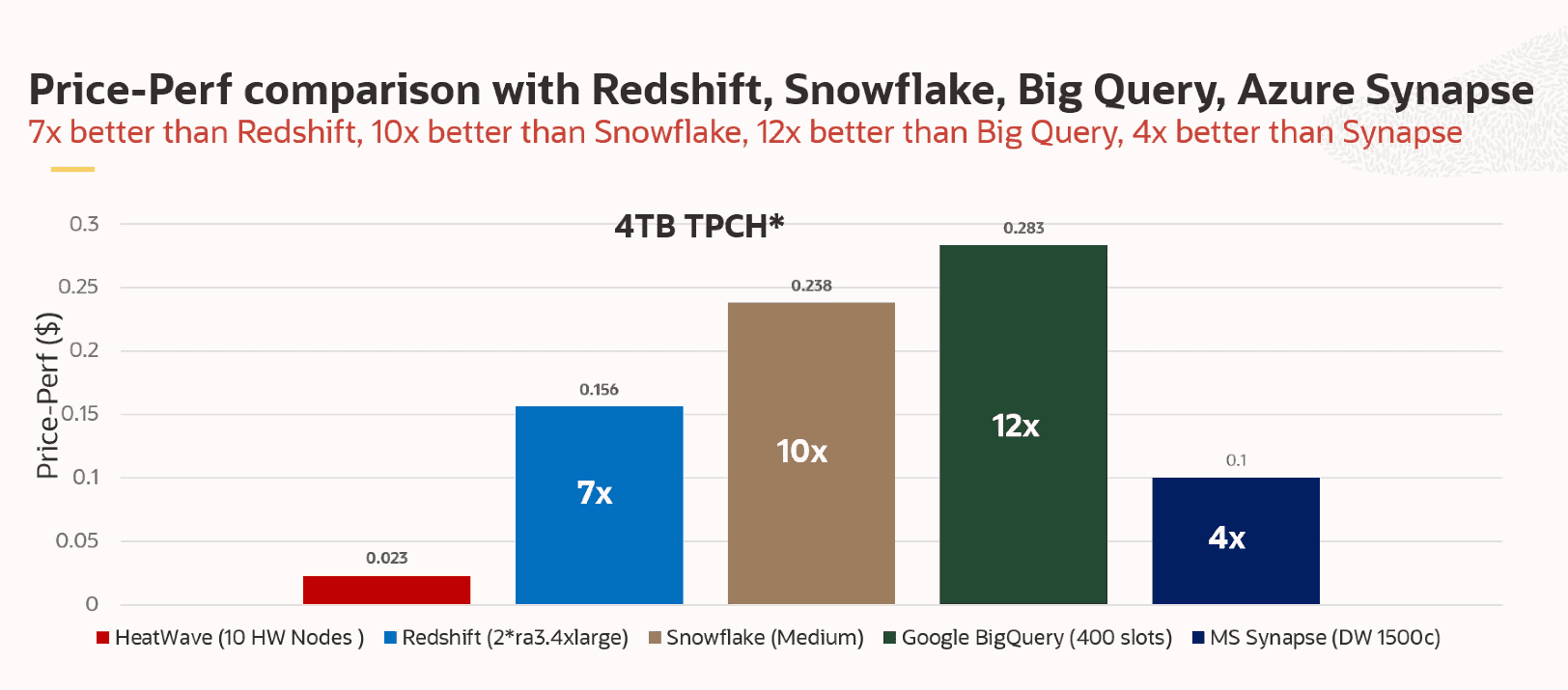
In addition to making MySQL HeatWave on AWS relatively easy to set up, Oracle also makes promises and statements about performance and cost. Based on a standard TPC-H benchmark run by Oracle, MySQL HeatWave on AWS is twenty times faster than AWS’ own Redshift database. On top of that, Oracle claims it is also seven times cheaper. Below are two graphs showing the ratios between the major players in the market, according to Oracle’s benchmark.
MySQL Autopilot
An important component of MySQL, especially for its price-performance compared to its competitors, is Autopilot. MySQL Autopilot is basically an automation feature. Using machine learning, Autopilot ensures that each workload performs optimally. It does this for the entire lifecycle of the application: provisioning, data management, query execution and failure handling. We won’t discuss Autopilot in detail here. We will stick to the two new features that are added today; auto thread pooling and auto shape prediction.
Auto thread pooling should ensure that the throughput is as high as possible and does not collapse at higher concurrency. Autopilot determines the optimal number of transactions to maintain this performance.
Auto shape prediction does what the name implies. Autopilot determines the optimal size (shape) to be used to achieve the best price-performance. If there is over-provisioning, Autopilot will advise downgrading, if there is under-provisioning it will advise upgrading.
All in all, Oracle has today taken yet another step in making its cloud services available to an ever-expanding public. Whether that audience will actually purchase these services is, of course, the question. If the price-performance ratios Oracle showed us during the briefing are representative and therefore also apply to other benchmarks and workloads, then customers won’t ignore Oracle because of the cost component.