Neural networks (NNs) support all sorts of functions, from Tesla’s Autopilot controls to medical diagnoses and personalized advertisements. Like the human brain on which they are based, the precise workings of an NN are notoriously difficult to track. Research by Anthropic is making a better understanding of the technology significantly easier to achieve.
NNs can target both text and images, but always apply a network of neurons that individually perform simple calculations and communicate with each other. Anthropic explains that while the mathematics of neurons is fully known, it’s unclear why a neural network exhibits certain behaviour as a result of those calculations.
This creates a problem all too familiar to generative AI applications, which are structured differently but create similarly unpredictable outputs. A neural network should be as secure as possible and traceable in its actions, Anthropic argues. After all, this makes them more viable for all sorts of use-cases. Given they’re beneficial for detecting medical problems on a large scale, generating logistics routes and controlling vehicles, for example, this opens up a world of possibilities.
Tip: Liquid neural networks: how a worm solves AI’s problems
Constituent parts
NNs are trained on data and can draw conclusions based the information it’s given. It does so by making connections between neurons. In the process, the same neurons can be activated in completely different cases. Anthropic explains that a single neuron within a vision model can respond to both a cat’s face and the front of a car, for instance.
Anthropic examined a transformer language model consisting of 512 neurons. Such a model can capture context from a data set and then apply this information to new data. Examples of practical applications of this can be found in real-time text and speech translation or fraud detection. The researchers split the 512 neurons into 4096 features, each of which has a particular function. This allowed the researchers to see within an individual neuron and know why it was activated.
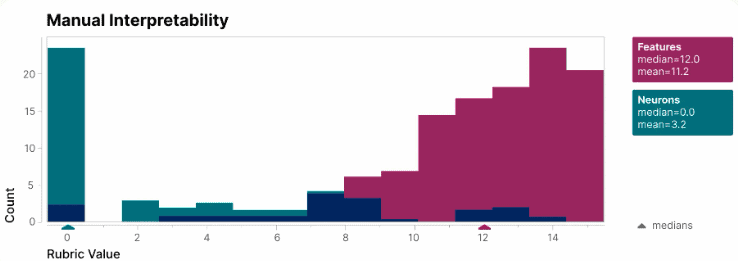
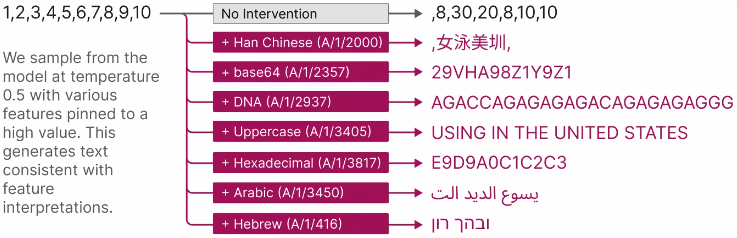
Through a blind test, features proved to be a lot easier to interpret what a neural network did with the given input than just the activations of neurons. Splitting the model up into its features also makes an AI model more controllable. For example, an output can be changed predictably by manually activating certain features.
Under the hood
In essence, Anthropic’s research shows how to better look under the hood of a neural network. By seeing how the model converts an input into an output, it can be further refined to avoid undesirable results. Anthropic itself states that it is essential to raise the security and reliability levels of AI so that society as a whole and businesses, in particular, can take advantage of it.
Getting to the bottom of AI’s inner workings will also be able to help legislation. For example, a self-driving car’s decision-making process could be better understood, making them increasingly trustworthy. There are countless other examples (such as applications in the medical, financial or logistics worlds) that could be better regulated if the creator of an AI model can demonstrate its safe operation in concrete form.
Anthropic refers to “Mechanistic Interpretability,” a research goal in which behavior of AI models can be controlled from within. With the new research, it hopes to have created a breakthrough in this area, although it is still working on developing its research in a way that scales.
Also read: Amazon invests $4 billion in Anthropic for better AI proposition