
Databricks announced that it’s expanding its Lakehouse Platform at its Data + AI Summit.
Databricks is positioning the lakehouse more and more aggressively. Whereas the company still described itself as a unified analytics provider three to four years ago, it now revolves around the lakehouse paradigm. Unified analytics is still the goal, as lakehouses follow the idea of deploying an integrated tool, but the word is used a lot less these days. Instead, Databricks is fully committed to bringing together the best aspects of data warehouses and data lakes in an architecture called the lakehouse.
During the Data + AI Summit, Databricks shared some benchmarks with us. The lakehouse scores well in terms of price and performance. Although that’s a good thing, there are also tests in which competitors score better. Therefore, we looked at what’s new and how the platform’s developing.
Tip: Will Databricks lakehouses change the AI and data world?
Lakehouse tailored to sectors
If there is one thing that stands out in the platform’s development over the past few months, it’s that lakehouses are increasingly being customized for the market. In this case, customized means that it’s built for specific sectors. For these sectors, Databricks makes Solution Accelerators available, a term for targeted notebooks and best practices. They focus on common use cases to save on discovery, design, testing and development time.
This year, Databricks released lakehouses for retail, financial service, healthcare and media companies. They receive, for example, datasets and libraries for applying data management, artificial intelligence and analytics in their sector. Think of fraud detection or the classification of medical images.
Expansion of governance capabilities
Prior to the Data + AI Summit, CEO and co-founder Ali Ghodsi told us that everything presented as innovative during the event has the goal of advancing governance, warehousing, engineering and data science. On the data governance side, Databricks will bring advanced capabilities to Unity Catalog. This solution was announced at last year’s Data + AI Summit, went into preview and will become generally available on AWS and Azure in the coming weeks.
Unity Catalog brings “fine-grained governance and security to lakehouse data using a familiar open interface”. The centralized governance solution for all data and AI assets features search and discovery, automated lineage for all workloads with the performance and scalability for a lakehouse on any cloud.
Data lineage was added to Unity Catalog earlier this month. Thereby, Databricks extended the governance capabilities for lakehouses. Companies gain insight into the entire data lifecycle. It provides insight into where lakehouse data comes from, who created it, how it has been modified over time and how it’s used for data warehousing and data science workloads.
Databricks Marketplace and Cleanrooms arrive shortly
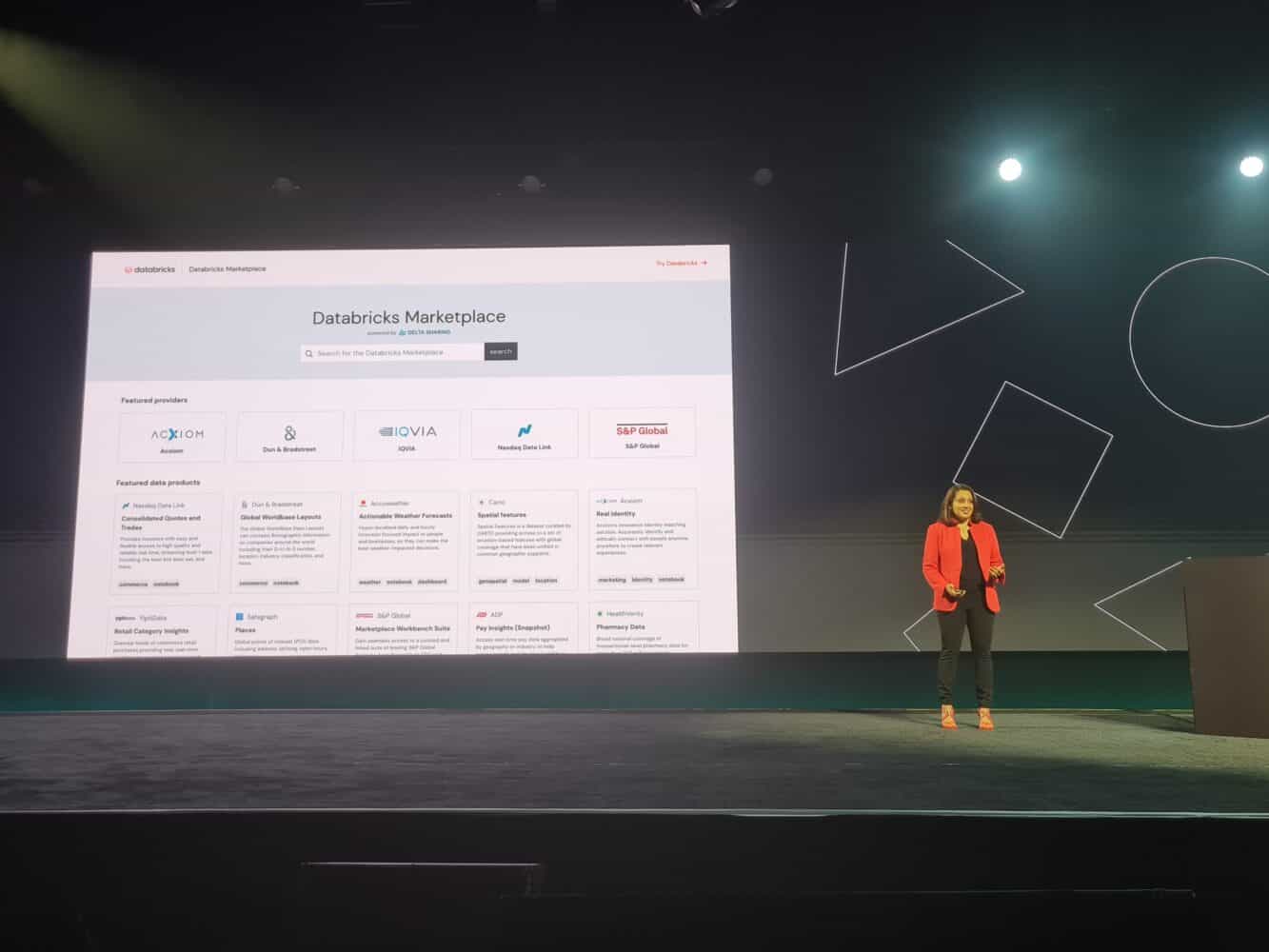
Another significant update to the Lakehouse Platform is the Databricks Marketplace, which will become available in the coming months. The company aims to create an open marketplace for the distribution of data and analytics assets. Data providers can offer assets on the marketplace, such as data tables, files, models, notebooks and analytics dashboards. For organizations that want to get started with data, this is a simple and quick way to start analyses and gain insights. As an example, Databricks mentions subscribing to existing dashboards rather than building dashboards for reporting.
The Databricks Marketplace enables providers to share data without having to move or replicate it from their cloud storage. It is possible to deliver data to other clouds, tools and platforms.
In addition, Cleanrooms provides upcoming functionality for data sharing and collaboration. This feature is particularly suitable for data sharing between companies, in a secure environment without needing replication. As an example, Databricks mentions media and advertising companies that want insight into the overlap of target groups and the reach of campaigns.
With Cleanrooms, Databricks wants to address the limitations of existing products. According to Databricks, alternative products have limitations because they only use SQL tools and risk data duplication between different platforms. Cleanrooms should allow organizations to collaborate easily, with the flexibility to run complex calculations and workloads using SQL, Python, R and Scala tools.
Data scientists can expect MLflow 2.0
As mentioned earlier, data science is one of the new features’ focus areas. Professionals that deal with data science can therefore get started with MLflow 2.0. Version 2.0 focuses on tackling the difficult and long process of getting a machine learning pipeline into production. This doesn’t just require writing code, but setting up infrastructure as well. Therefore, version 2.0’s MLflow Pipelines offer the possibility to handle operational details. Instead of setting up notebook orchestration, users can define the elements of the pipeline in a configuration file. MLflow Pipelines then handles the execution automatically.
Other features that data scientists can look forward to are Serverless Model Endpoints to support instant model hosting, as well as built-in Model Monitoring dashboards to help teams analyze model performance.
Performance Optimizer for Data Engineering Pipelines
Finally, it’s worth noting that Databricks is extending the Delta Live Tables framework launched earlier this year. This ETL framework gets a new performance optimization layer. The layer should speed up the ETL process and reduce costs. In addition, Enhanced Autoscaling was built to scale resources while considering changes in streaming workloads. Furthermore, there’s Change Data Capture (CDC) for Slowly Changing Dimensions — Type 2, which tracks any change in source data for compliance and machine learning purposes.
Final updates
In our opinion, the above updates clearly indicate the direction that Databricks is taking in the coming period. In addition to the above updates, Databricks announced several extra features, which you’ll find below:
- Databricks SQL Serverless is available as a preview on AWS, offering instant, secure and fully managed operations for improved performance at a lower cost.
- Photon, the query engine for warehouse systems, will become generally available on Databricks Workspaces in the coming weeks, further extending Photon’s reach across the platform.
- Open-source connectors for Go, Node.js and Python make it easier to access the lakehouse from operational applications.
- Databricks SQL CLI now allows developers and analysts to run queries directly from their local computer.
- Databricks SQL now provides the ability to execute queries on external data sources such as PostgreSQL, MySQL, AWS Redshift and others, without the need to first extract and load the data from the source systems (query federation).
Techzine is present at the Data + AI Summit this week. We’ll be reporting any important developments announced.