
The new Open Platform for Enterprise AI (OPEA) will push for open-source AI adoption. Its first task will be to develop open standards for RAG, or Retrieval-Augmented Generation.
OPEA is a product of the LF AI & Data Foundation, which in turn has been a spin-off of the Linux Foundation since 2018. The goal of the OPEA initiators is, not entirely surprisingly, exactly what the name suggests: to drive an open-source AI ecosystem for business use. The 10 Premier members include AWS, Huawei, Intel, IBM, Microsoft and SAS, among others.
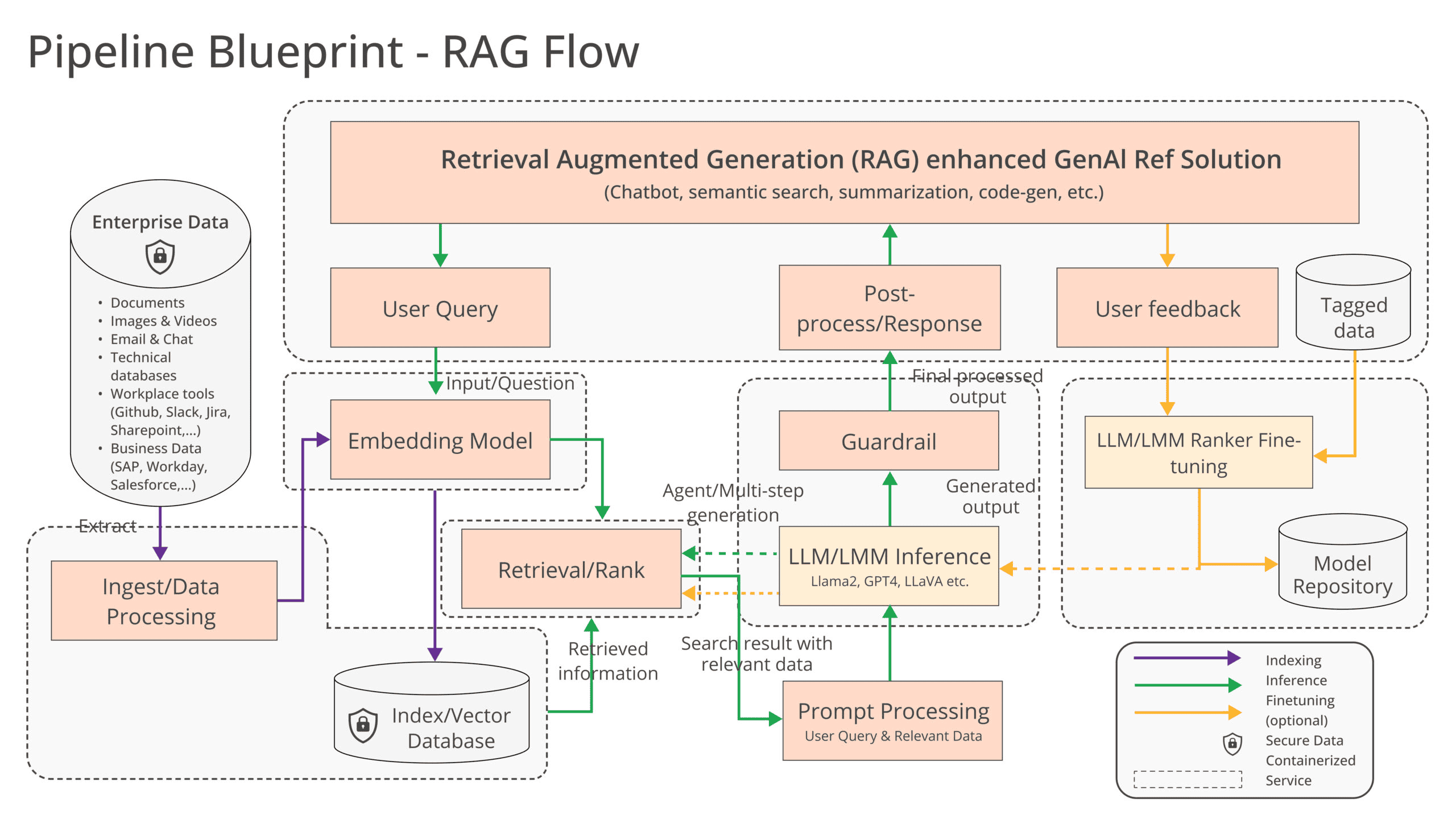
RAG is considered an important means of making AI models suitable for deployment within organizations. Pre-trained models can use this method to access internal documents (retrieval) to enrich (generation) their AI outputs. This lets LLMs capture the context of their own business operations without requiring models to go through a time-consuming and costly training or fine-tuning process. The added benefit is that the data can be updated in real-time, important for banks, for example, to analyze the current financial market.
Also read: What is Retrieval-Augmented Generation?
Against the fragmentation of tools
RAG is a good AI problem to address through OPEA, as organizations that are hesitant about AI adoption can be won over with the increased accuracy of this method. Still, there is much to standardize in the area of generative AI. At this early stage, there’s a worrying “fragmentation of tools, techniques and solutions,” the LF AI & Data Foundation concludes. The goal is therefore to create standardized components “including frameworks, architecture blueprints and reference solutions.” Crucially, these offerings must be production-ready with the required performance, interoperability and reliability.
Competition for the OPEA initiative certainly exists, and it comes from the proprietary corner. Where Intel and AMD, for example, have built their AI stack with open-source software and hardware that supports this approach, Nvidia is opting for proprietary solutions in both areas. This contrast is significant, as the latter currently largely controls the enterprise AI world. It is up to everyone else to ensure that development standards like Nvidia’s own CUDA will gradually lose out to open standards.
Tip: Intel and Nvidia have radically different visions for AI development
Ecosystem is building
In any case, the overall membership of the LF & Data Foundation is large. Parties such as Anyscale, Datastax, Hugging Face, the MariaDB Foundation, Red Hat and VMware (by Broadcom) will all contribute to the initiative. The end result should lead to “open, multi-provider, robust and composable GenAI systems.”
Tip: Databricks releases DBRX: open-source LLM that beats GPT-3.5 and Llama 2