
AWS released new functionality for storage service Elastic Block Store (EBS). The ‘crash consistent snapshots’ feature should make multi-volume snapshots for single EC2 instances simpler and cheaper.
AWS EBS is typically used to back up key applications, workloads and other data as part of a backup and disaster recovery plan.
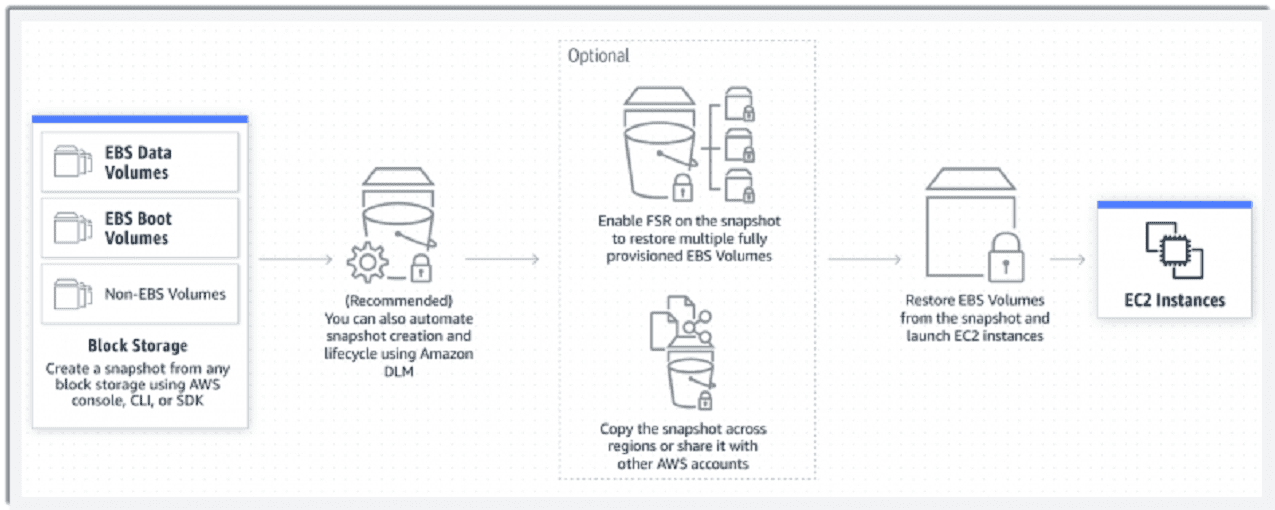
Backups can be created in several ways. Some users opt for a snapshot of an individual EBS volume. Others create multi-volume EBS snapshots associated with a single AWS EC2 instance. These snapshots contain all I/O activity data. This allows customers to restore their EBS volumes to the exact state at the time the snapshot was taken.
Crash consistent snapshots
Multi-volume snapshots aren’t perfect. For instance, it’s been difficult to create multi-volume snapshots of EBS volumes that only include some of the volumes associated with an instance. The process required several API calls to be made.
The new crash consistent snapshot feature for AWS EBS should simplify multi-volume snapshots of specific EBS instances attached to a single EC2 instance. Users can now select the volumes they don’t want to include in the multi-volume snapshot while creating the snapshot.
The selection can be made through a single API call or the Amazon EC2 console. According to AWS, the feature lowers the costs of running snapshots. Furthermore, crash consistent snapshots for subsets of EBS volumes are supported by Amazon Data Lifecycle Manager policies. This should help customers further automate the snapshot lifecycle.
New storage functionality
AWS also announced new storage functionality with the introduction of Amazon File Cache. This solution should help accelerate and simplify hybrid cloud workloads. The service delivers a high-speed cache on AWS to process file data, no matter where the data is stored. The service essentially provides a temporary high-speed storage location for data stored on on-premises file servers, in-file servers or object stores on AWS.
The service allows users to create distributed datasets that can be made available to file-based applications in AWS’ public cloud environment. The datasets have a common view, low latency and throughput of hundreds of GB/s.
The service is especially beneficial for cloud bursting and hybrid workloads, according to AWS. Use cases include media rendering and transcoding or automating electronic design workloads.
Tip: Data privacy: from necessary security step to competitive advantage