
Swami Sivasubramanian is responsible for data and machine learning at AWS. In a 2-hour keynote, he explained how to develop a data strategy using a variety of AWS solutions. In between, he also announces the necessary product updates so that organizations can extract even more or easier value from their data.
Sivasubramanian kicks off by stating that every organization needs a good data strategy. He argues that data is always better than intuition. A statement you can take to your organization’s management. This will undoubtedly generate the necessary discussions.
As an example, he cites Amazon. The entire company is built on data. In the first versions of Amazon.com, recommendations were already made when buying books, which books you should also read, or which books others are also buying. At that time, this was not determined with machine learning but simply by hand, perhaps based on sales figures. By now, this is undoubtedly a very sophisticated machine-learning model.

Developing a data strategy is not easy.
Developing a good data strategy is not easy. Data must be accessible, this means building integrations with a variety of tools. This requires pipelines but also a good structure so it can be used today, but also in the future. You don’t want to replace or change your data strategy and its core every year because your business requirements or solutions have changed. Finally, there is governance, compliance and security because data must be stored securely and not be accessible to everyone.
Sivasubramanian argues that organizations can no longer avoid data. Data is the genesis for modern invention.
Data is the genesis for modern invention
There is no single database or analytics tool to extract value from your data
There are some vendors who claim to be able to provide some sort of all-in-one product for your data and analytics. Frankly, that sounds the most ideal. Just one application where you can do all your analytics. However, Sivasubramanian is clear that it doesn’t work like that, stating that the top 1000 AWS customers use more than ten different databases and analytics tools from just AWS. In other words, it is impossible to analyze everything with a single database or analytics tool.
Of course, hybrid forms can be thought of, such as Snowflake, where you can bring together different types of data. Where you can use the internal analytics tools, but can also integrate well-known BI solutions, such as Tableau, for example, immediately Snowflake.

Tying everything together
It is clear from this keynote that AWS has taken a good look at what they think is the best way to make data more accessible for analytics. The conclusion is that they are making the different data platforms integrate better with each other. They saw many customers building pipelines between Amazon Aurora and Amazon Redshift, for example, or between Apache Spark and Amazon Redshift. That is no longer necessary because AWS has now developed out-of-the-box integrations, so that data can be shared in real-time.
At the same time, they are making Amazon Athena, a simple analytics application that allows you to do SQL-based analysis, available for Apache Spark.
It paves the way for doing data analytics as easily as possible and ensures that organizations can really start building on data. With that, data becomes mission critical. Something Redshift was not yet in our view.

Data is mission critical and now so is Redshift
Another important announcement is that Redshift will also be available in a multi-az variant. In other words, in multiple availability zones with automatic failover. If an entire region goes down, the data remains available from another region (availability zone). Previously, companies had to store Redshift backups in other regions and make them available in case of outages or problems. That takes minutes to bring back online, however, for some organizations that takes far too long. Thus the move to now make Redshift available in multiple availability zones with automatic failover.

80% of data is unstructured or semi-structured and requires ML
Sivasubramanian reveals that 80 percent of data worldwide is unstructured, or semi-structured. In any case, the data is not directly usable in a database because it is stored in images or documents. To turn this into readable and reliable data, organizations must use machine learning.

This is where Amazon SageMaker comes in. It allows companies to create, train and use their own models to do analysis on unstructured data and then turn it into structured data.
Amazon SageMaker is one of AWS’s most successful solutions. As an extension to SageMaker, Sivasubramanian is now introducing support for Geospatial ML. Machine learning models on geographic maps. Useful for organizations that need to plan cities or take action on natural disasters. AWS has also developed some standard ML models that you can let loose on geographic maps, for example to detect roads on satellite images. In the event of a major flood, machine learning can be used to determine which roads are still accessible and which are not.
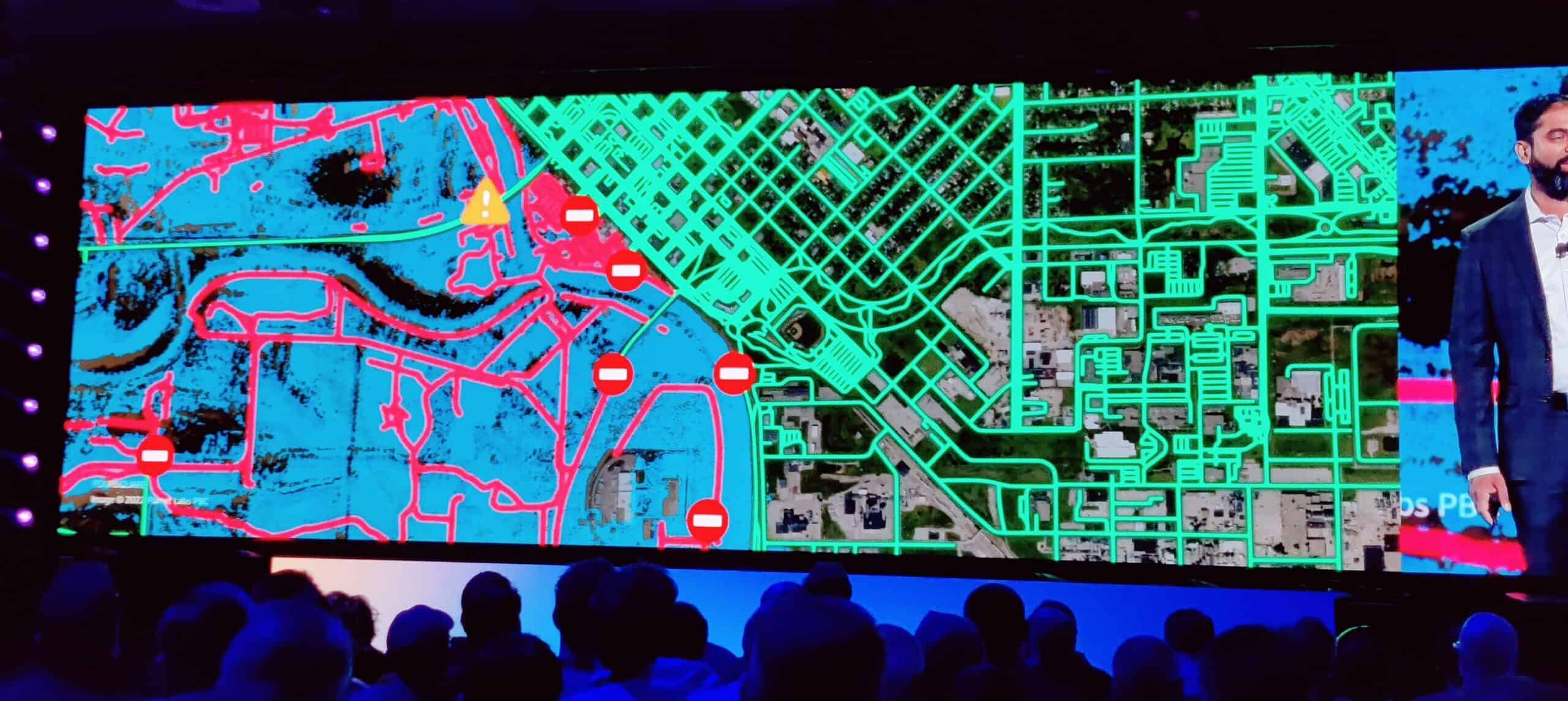
Ensuring quality and freshness
As an organization, you can now maintain a central mission-critical data lake in Amazon Redshift. You can also, as mentioned earlier, update it automatically through the connections and integrations with Amazon Aurora and Apache Spark. However, you must not lose sight of data quality. To control this as well, AWS is now introducing AWS Glue Data Quality.

Within AWS Glue Data Quality, you can set up rules that new (incoming) data must meet. Furthermore, the system can issue alerts if the influx of data declines because the quality requirements may be too high or the delivered information simply falls short. As an organization, you can then review and improve your incoming data streams or possibly adjust the requirements the data must meet.
Whenever possible, you want to automate the refreshing and adding of data as much as possible. One way to do that is through Amazon Redshift auto-copy from S3. A solution that was presented at re:Invent. You can have applications deliver data as an export into an S3 bucket, this new auto-copy tool will automatically import the data into your Redshift data lake.
In addition to Amazon Redshift auto-copy from S3, Amazon Sagemaker Data Wrangler and extensions to AppFlow were presented. With SageMaker Data Wrangler, you can import data from SaaS solutions and third parties for machine learning purposes. AppFlow lets you import data from well-known SaaS solutions for sales and marketing into various AWS services. AWS presented 40 new connectors for this. From Facebook Ads, Google Ads and LinkedIn Ads to Google Analytics 4, ServiceNow, Slack and Snowflake.

Meanwhile, the various solutions AWS offers allow you to connect the AWS data services to hundreds of data sources on the Web. Ultimately with the goal of bringing all of your organization’s data together in a data lake and being able to do analytics within your data strategy.
Data governance is high on the agenda
Securing data is higher on the agenda for many organizations. Not only because of stricter regulations but also because data breaches and leaks are not good for your reputation. Organizations are therefore often already busy with a data strategy around governance and compliance. They want to get an overview of their data and who has access to it.
AWS is now jumping on this with some new solutions. For example, the company presented Amazon GuardDuty RDS Protection. A tool to protect data in Aurora with Intelligent Threat Detection. This uses machine learning to detect and stop suspicious activity.
For Redshift, AWS is now introducing Centralized Access Controls for Redshift Data Sharing. This allows you to centrally control who has access to Redshift data. This can be set up on a column and row level by using AWS Lake Formation.
Also for SageMaker, AWS is now introducing Amazon SageMaker ML Governance. A tool where you can set who has rights to what within a ML-modal. With the goal of being able to provide governance but also audits with the right information.
Amazon DataZone
Finally, there is Amazon DataZone which we also reported on yesterday. With DataZone an organization can create a catalog to record what data it has and what columns it consists of. Links can also be made to the data source. Other employees in the organisation can search the catalog and request access to those data sets for certain projects or purposes. For example, to run a marketing campaign on that data.

To get access to the data, an employee has to create a project within DataZone and tell who needs access for which purpose. For what purposes will the data be used? By using DataZone the organisation has a complete overview of all data, how it is being used and who has access.
DataZone is also API-driven, so data can be retrieved directly from Amazon DataZone, which is possible because of the direct links to the data sources.
DataZone also uses machine learning to make those links and to turn complex column names into readable fields for people searching the catalog. For example, sales_mgr is converted into Sales Manager automatically.
Conclusion
We are at AWS re:Invent for the fifth time this year, we can conclude that in all these years AWS has put a lot of work into developing databases, analytics tools and machine learning. For developing your data strategy, AWS basically has everything you need, but let’s face it, it’s not very easy. We would always recommend hiring a specialist.
Organizations that want to design and build their data strategy from scratch can do so in AWS. However, there are quite a few AWS solutions that can play a role in this and it is difficult to explore them all on your own. That’s why the advice is to work with a partner who has the knowledge and certifications. They can also help you achieve results faster, which at the end of the day may be cheaper than doing the research yourself. In addition, AWS offers the necessary things out-of-the-box and has standard ML models you can use, but it is certainly not a specialist in, for example, HR, sales, service or marketing. For those kinds of purposes, you’re better off with a SaaS specialist. One pitfall is that some organizations want to reinvent the wheel.
We think organizations that want to improve their customer experience or sales journey with data are better off by first taking steps with a specialist in that area. For example, use Salesforce to optimize sales, service and marketing data and use their solutions to improvate the customer experience. Or Workday to provide a better experience to employees. Why would you develop sales analytics and predictions when Salesforce can provide you those out-of-the-box?
What makes your organization unique? What data do you have that you can apply machine learning to that will add value and make your organisation run better or be more efficient? AWS has quite a few use cases that you can learn from. Whether you are an organization in the manufacturing industry or an agricultural enterprise working with IoT sensors. Their are many use cases in which you can collect specific data.
Ultimately, you need to think carefully beforehand about the purpose of your data lake. What should your data lake deliver? What questions should your data lake be able to answer? Simply collecting a lot of data will yield nothing except a large cloud bill. Then you also have to ask yourself the question, is it wise to analyze that datayourself or are there specialists who can do this much better and cheaper? Above all, you have to develop machine learning models and analyze data that you have the most knowledge and experience in, because that is where you can make a difference.
Eventually, you will be left with a number of use cases that are interesting and for which you can develop a data strategy, but also quite a few use cases for which it is better to choose a specialist. If the sales or HR data from such a SaaS specialist can still provide added value in addition to the data you have collected yourself, you can always import the data into Redshift and perform combined analyses.
We agree with Sivasubramanian that data is the genesis for modern invention, but it is quite complicated and a data strategy should not be taken lightly.
Also read: AWS shows a lot of power at re:Invent 22 opening keynote