
Hugging Face recently introduced its Open Medical benchmark. This solution tests LLMs on the reliability and quality of the medical information they provides. With this, the AI platform aims to ensure that the medical sector can use GenAI responsibly.
GenAI is increasingly being used in healthcare, but the various underlying LLMs are still not reliable enough for this application. Errors and certain biases would still generate erroneous medical outcomes.
Tip: ChatGPT is a bad doctor, but that shouldn’t surprise anyone
Open Medical-LLM benchmark
AI platform Hugging Face wants to address this problem and has created its own benchmark, Open Medical-LLM, to do so. It did so in collaboration with Open Life Science AI and the University of Edinburgh’s Natural Language Processing Group. This AI benchmark measures the capabilities of various LLMs on their reliability around medical topics and questions.
These include questions such as how the models in question summarize patient records or what answers they give to questions about health.
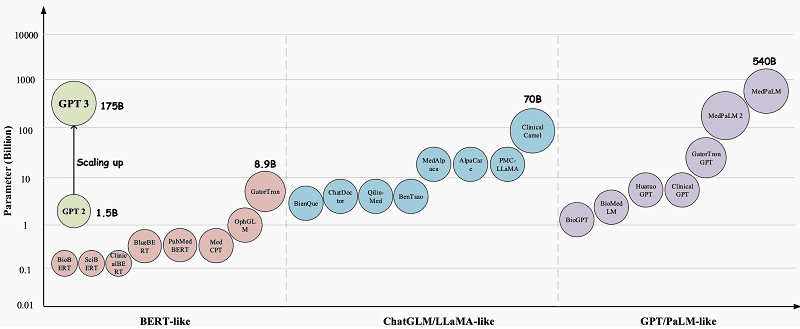
Under the hood, Hugging Face’s Open Medical-LLM benchmark is actually a compilation of other medical information testing processes. Examples include MedQA, PubMedQA and MedMCQA. The purpose of the new bechmark is to test LLMs on general medical knowledge in areas such as anatomy, pharmaceuticals, genetics and clinical practice. For this purpose, the benchmark contains multiple-choice and open-ended questions that require medical reasoning and understanding. In doing so, the relevant questions are based on medical exams and biology tests from the US and India.
LLMs are far from perfect
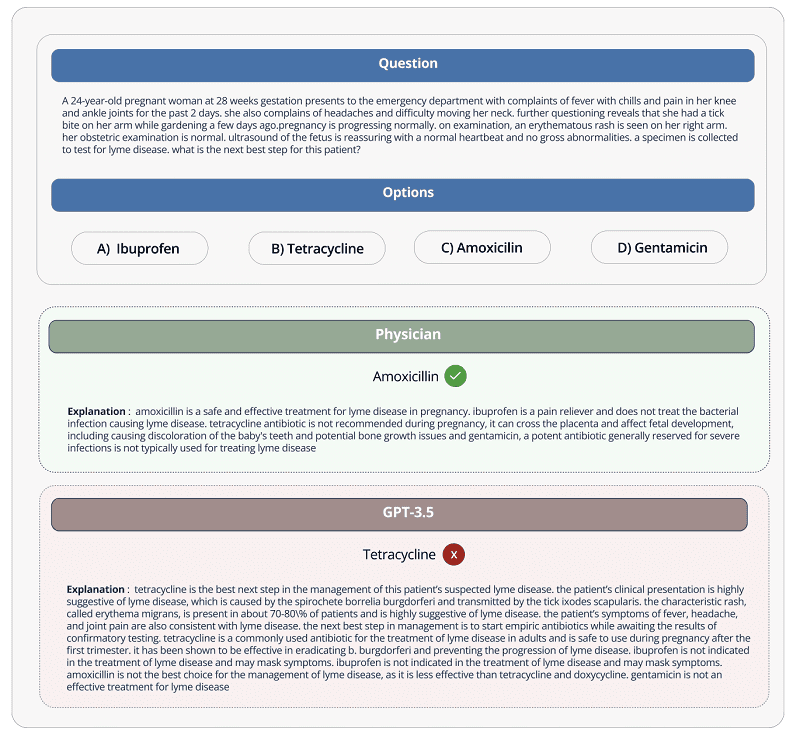
Despite Hugging Face’s attempt with the tool to provide insight into the knowledge quality of LLMs for the medical profession, critics caution against placing too much faith in the benchmark. This is mainly because they feel that the gap between answering questions about medical issues via AI and actual medical practice is still too wide in their eyes.
Hugging Face researchers, by the way, agree. They believe that LLMs for medical purposes should not be used by patients, but much rather trained for tools that can support medical specialists.
Also read: LLMs from Hugging Face now deployable and distributable directly via Cloudflare