Chinese LLM developer DeepSeek has unveiled its R1 series of large language models (LLMs), optimized specifically for reasoning tasks. According to the company, these new algorithms deliver superior performance compared to models like OpenAI’s o1.
The R1 series is powered by two key algorithms: R1-Zero and R1. These models leverage a Mixture of Experts (MoE) architecture, featuring 671 billion parameters. This architecture is designed to reduce inference costs by activating only the neural networks needed to address a specific query rather than the entire model.
In practice, DeepSeek’s R1-Zero and R1 activate less than 10% of their 671 billion parameters when processing prompts.
Innovative training methods
DeepSeek attributes the strength of its LLMs to the innovative way they’ve been trained. For R1-Zero, the company departed from traditional methods used for reasoning models.
Typically, these algorithms are trained using reinforcement learning and supervised fine-tuning. Reinforcement learning relies on trial-and-error techniques, while supervised fine-tuning improves output quality by providing step-by-step examples.
With R1-Zero, however, DeepSeek skipped the supervised fine-tuning phase. Despite this, the model still demonstrates reasoning capabilities, such as breaking complex tasks into smaller, manageable steps.
While R1-Zero offers many features, its output quality falls short. Responses are often repetitive, difficult to read, and tend to mix multiple languages within a single output.
Introducing the improved R1 model
To address these limitations, DeepSeek developed the R1 model, which incorporates supervised fine-tuning. This adjustment has significantly improved output quality.
DeepSeek claims that R1 outperforms OpenAI’s o1-LLM on various benchmarks. On others, it lags behind by less than 5%, narrowing the gap significantly.
Additional models
Alongside R1-Zero and R1, DeepSeek has introduced several smaller, more hardware-efficient LLMs. These models range in size from 1.5 billion to 70 billion parameters.
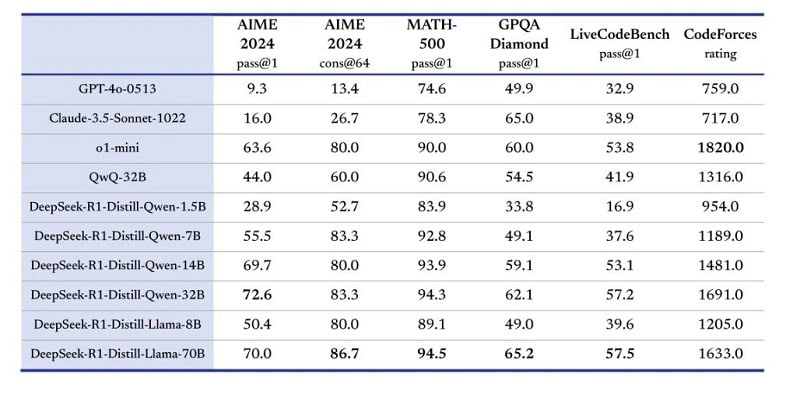
Under the surface, these LLMs are based on the open-source Llama and Qwen sets. The R1-Distill-Qwen-32B model is said to outperform even scaled-down versions of OpenAI’s o1-mini or o-models on various benchmarks, according to DeepSeek.
The source code for DeepSeek R1-Zero and R1 is now available on Hugging Face.
Also read: DeepSeek-V3 overcomes challenges of Mixture of Experts technique