
Meta has released an open-source model that can compete with GPT-4, GPT-4o, and Claude 3.5 Sonnet. The big difference is that Meta takes an open approach with Llama 3.1, while the competing top models are closed-source. With closed-source, the models can only be called via a paid API. Will developers soon mainly use open-source AI?
With 405 billion parameters, Llama 3.1 is very capable. This number says something about how well the model can handle detailed, complex tasks. In theory, 405 billion parameters make the output very precise. However, comparisons with GPT-4, GPT-4o, and Claude 3.5 Sonnet are difficult because the exact number of parameters of these models are unknown. But the benchmarks we discuss later in this article do give an indication of the new ratios in the market.
Meta-CEO Mark Zuckerberg foresees big changes in the developer community thanks to what Llama 3.1 achieves. “I believe the Llama 3.1 release will be an inflection point in the industry where most developers begin to primarily use open source,” Zuckerberg said. According to him, open-source is important for building an ecosystem, ensuring security, and further developing the model.
However, while a large model may initially seem interesting, it also has drawbacks. Namely, such a model requires a lot of computing resources and energy. Meta already consumed 30.84 million GPU hours and produced 11,390 tons of CO2 emissions for training the model. Moreover, the scale is too challenging for the average developer to work with.
Please note that this article only discusses the Llama 3.1 405B and not the smaller models 70B and 8B.
How does Llama 3.1 perform?
The most exciting aspect to assess now is the performance of Llama 3.1, by looking at the benchmarks. Those can be found below. In the market, language comprehension, programming and math are generally considered the most important competencies of a model. In those categories, MMLU, Human Eval and GSM8K are the standards, respectively. In the language comprehension category, there are few differences in the benchmarks. Coding, however, Claude 3.5 Sonnet does significantly better. The difference in math is also small, although Llama 3.1 scores narrowly best here.
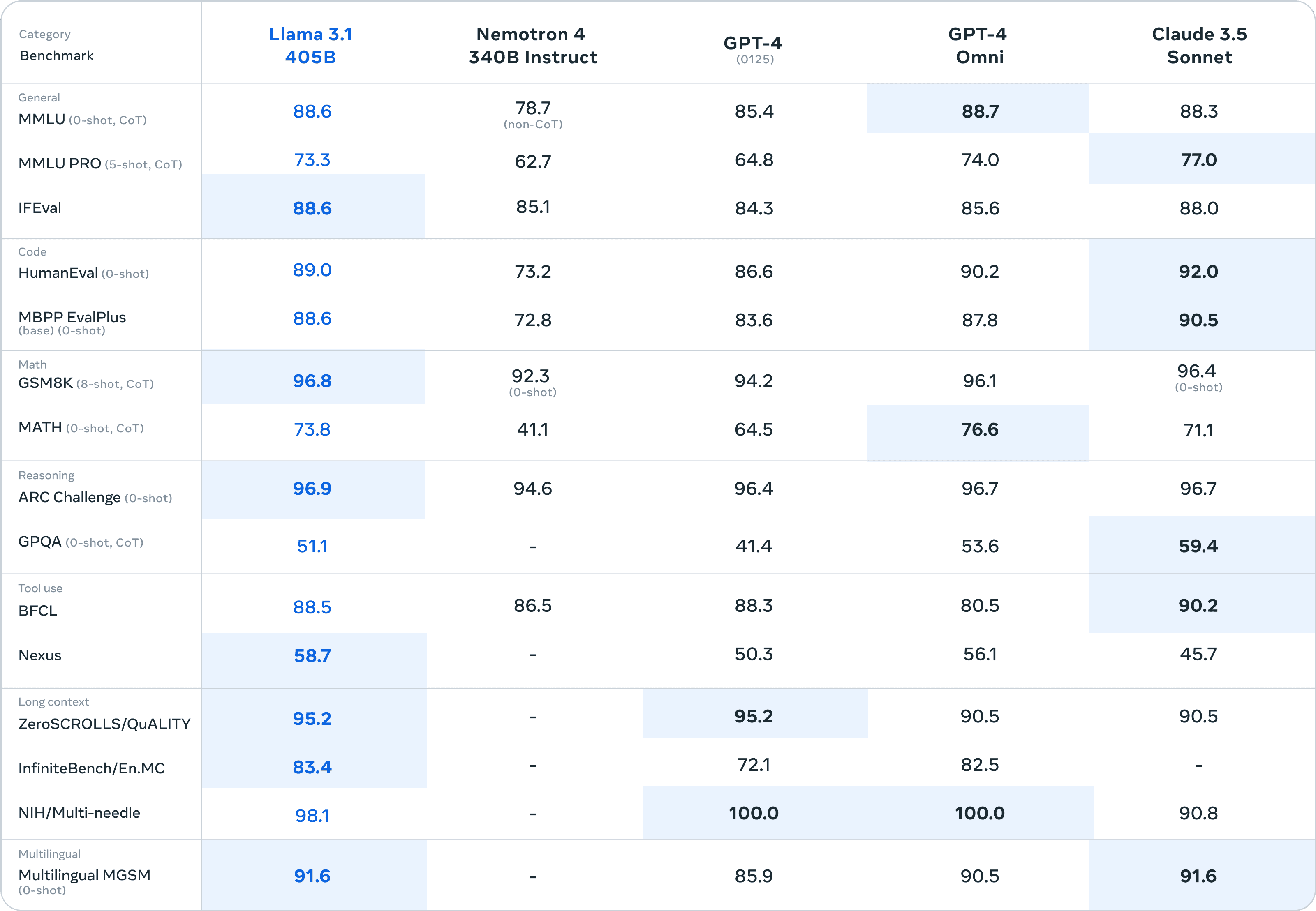
The new Meta model performs significantly better in long contexts and reasoning. This can be partly explained by the 405 billion parameters, which come in handy in such situations. Ultimately, all benchmarks provide a reliable indication, Meta evaluated the model based on more than 150 benchmark datasets. Still, practice must show how exact the performance is.
Meta reaches new heights with decoder-only transformer
The benchmarks show that Meta, after previous Llama versions, can now, for the first time, really compete with other companies’ closed models. What contributes to this performance besides the parameters is the architecture. This is a decoder-only transformer architecture, where a prompt is input in its entirety. This is different from the mixture-of-experts (MoE) architecture, which is often chosen with the latest models. In that case, input is analyzed by different experts specializing in certain tasks, which makes the output accurate.
Meta indicates that the challenge was mainly in training Llama 3.1 on more than 15 trillion tokens. This also explains the high number of GPU training hours. Meta itself used more than 16,000 of the very powerful Nvidia H100 GPUs, highlighting the scale of the project. As a result, the development process had to remain straightforward, which explains the choice of a standard decoder-only transformer. In addition, Meta followed an iterative post-training procedure, with each round using supervised fine-tuning and direct preference optimization. This allowed Meta to create the highest quality synthetic data and improve performance in each round.
All in all, Zuckerberg thinks Llama 3.1 will follow a similar path to Linux, which has also become a standard for developers. “In the early days of high-performance computing, the major tech companies of the day each invested heavily in developing their own closed source versions of Unix. It was hard to imagine at the time that any other approach could develop such advanced software. Eventually though, open source Linux gained popularity – initially because it allowed developers to modify its code however they wanted and was more affordable, and over time because it became more advanced, more secure, and had a broader ecosystem supporting more capabilities than any closed Unix. Today, Linux is the industry standard foundation for both cloud computing and the operating systems that run most mobile devices.”
Llama 3.1 is available immediately via the Meta AI app. Since the model is still in preview, only a limited number of queries per week can be run for now. It supports English, French, German, Spanish, Italian and Portuguese.
Tip: Snowflake enters the LLM war with introduction of Arctic