
At NetApp Insight we witnessed one of the most fundamental NetApp product launches in decades. With NetApp AFX, it now claims to have a storage layer designed for AI, specifically for the inferencing workloads that many organizations want to run. In addition to new hardware, this new offering also brings some necessary new features in the area of software. The AI Data Engine steals the show in this regard. In this article, we take a closer look at what NetApp AFX and the AI Data Engine are and explain why this is such an important announcement for NetApp. The impact this launch could have on the company is huge.
Virtually all IT vendors use (sometimes misuse) AI nowadays to market new products and services. NetApp has been doing the same for several years. See here and here for two recent examples. This strategy seems to be working very well for the company, by the way. Earlier this year, IDC announced that NetApp is number one in the All-Flash market (systems without HDDs but with only flash storage). It reported growth of 16 percent compared to the previous year. This means it is growing faster than both Dell (which showed a decline) and even the darling of the All-Flash market, Pure Storage. Only HPE grew faster, but it has a much smaller market share.
AI projects fail due to poor infrastructure
With all the attention focused on AI, you might think that organizations are all dancing in the streets because of all the successes its use has brought. However, nothing could be further from the truth. Virtually all AI projects that organizations initiate themselves fail. According to NetApp, the underlying infrastructure plays an important role in this. It is simply not suitable for the AI workloads that many (larger) organizations are looking at. In particular, everything is still in its infancy in the field of inferencing.
With NetApp AFX, by far the biggest announcement the company is making during Insight this year, it now claims to offer a (start of a) solution for AI inferencing workloads that companies want to run. You could see this as the first real concrete implementation of the Intelligent Data Infrastructure vision that NetApp presented last year. That may be a slight exaggeration, because NetApp has not been idle over the past year. Still, it does feel a bit like that. In terms of hardware (and software), AFX is fundamentally different from anything else in NetApp’s SAN and NAS portfolio.
NetApp AFX: disaggregated and extremely scalable
If we break down what NetApp AFX is supposed to achieve, we can quote Sandeep Singh, SVP and GM Enterprise Storage at NetApp, who spoke during a session we attended this week: “NetApp AFX gives customers the performance to keep feeding the GPUs.” That was the underlying assumption, at least when it comes to inferencing workloads.
To achieve the necessary performance, storage must be scalable. This can only be done effectively and efficiently through a disaggregated architecture. This means that the compute layer of AFX is decoupled from the capacity layer. The compute layer handles things like data management and provides I/O. The capacity layer consists of NVMe flash storage. The AFX can scale to a maximum 128 (compute) nodes. 400G Ethernet connections take care of the network part. NetApp AFX scales enormously. The X in the name indicates this: we are talking about scaling to exabytes.
Decoupling enables scaling in multiple ways without overprovisioning. If you want higher performance, you add storage controllers. If you want to scale up capacity, you add boxes with flash storage. Bearing in mind that NetApp AFX, like AFF, is unified file and object storage, you are essentially creating a large storage pool for file and object workloads that the storage controllers can do smart things with and that is designed to scale in any direction that organizations want.
The above approach, decoupling controllers and storage, is not new, by the way. Pure Storage, in particular, has been focusing on this for some time, in its most extreme form with Pure Fusion. For NetApp, which traditionally has a more complex and deeply integrated stack than Pure, this is a major achievement. It must have been a huge task.
Perhaps needless to say, NetApp AFX, like the rest of the company’s portfolio (with the exception of StorageGrid and the E Series), is built on ONTAP. For many years, this has been the basis for everything NetApp develops. ONTAP ensures that NetApp can optimally implement its hybrid approach and, for example, offer deep integrations with AWS, Azure, and Google Cloud.

NetApp AFX has its own compute
If you look at the NetApp AFX rack above, it is clear that AFX is more than storage controllers and all-flash storage. In addition to an AFX 1K storage controller and NX224 NVMe enclosure, we also see the DX50. This is undoubtedly the most distinctive component of the NetApp AFX. NetApp refers to this component as a data compute node.
The DX50 is not a compute node on which you can run VMs or databases yourself. We should definitely not see it as an attempt by NetApp to enter that world. That’s what we hear from Jeff Baxter, VP of Product Marketing at NetApp. Inside the 1U-sized DX50, an Nvidia L4 GPU roars in combination with an AMD Genoa 9554P CPU, supplemented with 15 TB of storage in a U.2 form factor.
The DX50 is best seen as a counterpart to the DPUs found in servers, switches, and routers. The compute node allows you to add smart features to your data pipelines and offload them. And this is where the AI Data Engine comes in.

AI Data Engine adds a lot to NetApp AFX
The announcement of NetApp AFX is fundamental to NetApp (and the storage market) in several ways. Of course, the new disaggregated architecture is the basis. However, in our opinion, the addition of the DX50 and with it the AI Data Engine should not be underestimated. It adds four things that should make it easier for customers to build secure and efficient data pipelines. We discuss them briefly below.
The first two features of the AI Data Engine focus on retrieving and keeping data up to date. A Metadata Engine helps customers access data. Customers typically have data stored in silos, spread across multiple locations. Storage administrators can use the metadata engine to give data scientists and other colleagues access to the right datasets.
With Data Sync, they can also ensure that AI never uses old data. Here, NetApp uses tools such as SnapMirror and SnapDiff to synchronize and detect changes in a fully automated manner. Gagan Gulati, SVP and GM Data Services at NetApp, says that NetApp is using “the best it has to offer” to keep data up to date at all times.
When talking about AI, the conversation quickly turns to keeping it in check. This requires rules, policies, and limits. That is what Data Guardrails adds to the AI Data Engine. This feature ensures that sensitive data is always recognized as such. It also protects this data from improper use. Customers can also set policies to handle things in a fully automated manner. Finally, there are options for “blacking out” sensitive information and excluding it from use by AI applications or chatbots.
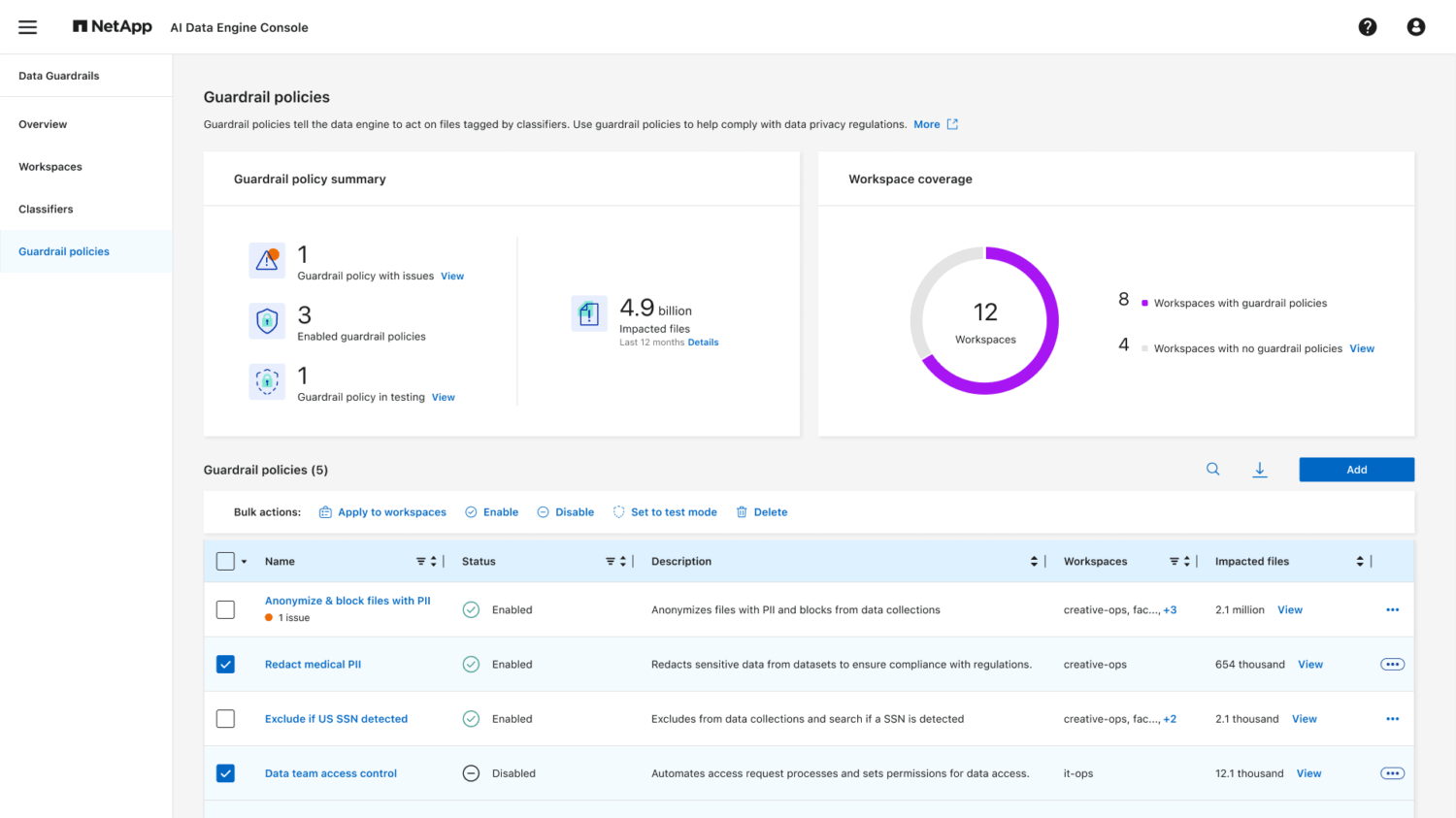
Data Curator: finally a solution for vector database bloat
The last of the four components of the AI Data Engine deserves its own paragraph, in our opinion. Data Curator solves a problem we have been discussing for a long time: the vectorization of databases for AI applications. This can cause data to grow to 10 to 20 times its original size. Last year at NetApp Insight, we discussed this in depth during a podcast we recorded on site. At that time, however, there was no solution available, even though our guest indicated that NetApp’s labs were already working on it.
With Data Curator in the AI Data Engine, NetApp now claims to have something that can reduce the increase. NetApp promises an increase of up to 5 times the original size of the data, we hear from Gulati. That can result in serious savings. Not only that, it should also improve the performance of AI workloads. After all, the vector embeddings need to be searched less often.
NetApp did not develop this new feature entirely on its own. The AI Data Engine was built according to the principles of the Nvidia AI Data Platform. Thanks to the vectorization APIs in Nvidia NIM and Nvidia’s inferencing microservices, among other things, it is possible to convert “normal” data for use in vector databases as efficiently as possible.
More compute nodes are coming
When it comes to compute nodes, it is important to emphasize that NetApp AFX is not inherently tied to the DX50 for running the AI Data Engine. This optional module from NetApp AFX can also be replaced by other models. In any case, support for Nvidia RTX PRO servers is coming. These contain RTX PRO 6000 Blackwell Server Edition GPUs.
One question that arises is whether there will also be support for compute nodes with GPUs from other providers. That is a question that Sandeep Singh was unable or unwilling to answer for us. Except, of course, for the usual obligatory answer that NetApp always keeps all options open.
Given the strong dependence of the AI Data Engine on the Nvidia Data Platform, as far as we can see, this would involve more than just putting a different GPU in a compute node. The software stack around and on top of it, something Nvidia has put a lot of work into in recent years, must also be in place to enable Data Curator, for example. In any case, we don’t see this happening anytime soon. AMD is now present in the DX50 (as a CPU), although Nvidia is also making great strides in that area. Think of the recent deal with Intel, but also of the proprietary CPUs it is working on.
Modularity offers flexibility
Finally, we would like to highlight a perhaps somewhat overlooked feature of NetApp AFX. As we mentioned earlier, the compute node is an optional component. This means that you can purchase and deploy NetApp AFX without this component. Potentially, NetApp is killing two birds with one stone with AFX. With a compute node for inferencing workloads in EDA, SQL, and VMware, without more HPC-related workloads.
HPC workloads can already run in combination with high-end AFF systems. However, if you want to add features such as checkpointing, which requires temporary buffers, you will need a second system. The NetApp E Series, for example, can be used for this purpose. That’s no longer necessary now.
NetApp intends to bring the AI Data Engine to other parts of the portfolio. When asked about the role of StorageGrid, NetApp-CEO George Kurian said AI Data Engine will be coming to StorageGrid too. FlexPod, the collaboration between Cisco and NetApp around converged storage, will also get it.
Conclusion: NetApp AFX heralds a new era
It should be clear that NetApp AFX is much more than a refresh. It is also much more than an extension of an existing offering. NetApp AFX is a new beginning for NetApp. At least, it can be and will be. By this, we do not mean that NetApp has discarded everything it has done and created so far and started over. With AFX, it has fundamentally restructured everything.
In the short term, NetApp AFX will mainly impact NetApp’s and its customers’ AI ambitions. For the longer term, we see several possible paths. One of them is that NetApp AFX will ensure that NetApp’s offering as a whole becomes much more unified. NetApp AFX could well become the underlying architecture and thus the underlying platform (with ONTAP as the OS) for the entire portfolio. This would permanently eliminate a frequently cited argument against the company’s products from some competitors, namely that NetApp has too many different platforms. From this perspective, NetApp AFX could fundamentally represent a new beginning for the company.